पेशेवर इंटरनेट खोजों के लिए आपकी आवश्यकता है विशेष सॉफ्टवेयर, साथ ही विशिष्ट खोज इंजन और खोज सेवाएँ।
कार्यक्रमों
http://dr-watson.wix.com/home - कार्यक्रम को संस्थाओं और उनके बीच कनेक्शन की पहचान करने के लिए पाठ जानकारी के सरणियों का अध्ययन करने के लिए डिज़ाइन किया गया है। कार्य का परिणाम अध्ययनाधीन वस्तु पर एक रिपोर्ट है।
http://www.fmsasg.com/ - कनेक्शन और रिश्तों को देखने के लिए दुनिया में सबसे अच्छे कार्यक्रमों में से एक सेंटिनल विज़ुअलाइज़र। कंपनी ने अपने उत्पादों को पूरी तरह से रूसीकृत और कनेक्ट कर दिया है हॉटलाइनरूसी में।
http://www.newprosoft.com/ - वेब साइटों से डेटा निकालने के लिए "वेब कंटेंट एक्सट्रैक्टर" सबसे शक्तिशाली, उपयोग में आसान सॉफ्टवेयर है। इसमें एक प्रभावी विज़ुअल वेब स्पाइडर भी है।
साइटस्पुतनिक – एक सॉफ़्टवेयर पैकेज जिसका दुनिया में कोई एनालॉग नहीं है, जो आपको उपयोगकर्ता के लिए आवश्यक सभी खोज इंजनों का उपयोग करके दृश्य और अदृश्य इंटरनेट पर इसके परिणामों को खोजने और संसाधित करने की अनुमति देता है।
वेबसाइट-वॉचर - आपको पासवर्ड-संरक्षित पेजों, मॉनिटरिंग फ़ोरम, आरएसएस फ़ीड, समाचार समूहों, स्थानीय फ़ाइलों सहित वेब पेजों की निगरानी करने की अनुमति देता है। के पास शक्तिशाली प्रणालीफिल्टर. निगरानी स्वचालित रूप से की जाती है और उपयोगकर्ता के अनुकूल रूप में वितरित की जाती है। उन्नत कार्यों वाले एक कार्यक्रम की लागत 50 यूरो है। लगातार अद्यतन किया गया।
http://www.scribd.com/ दुनिया में सबसे लोकप्रिय मंच है और विभिन्न प्रकार के दस्तावेज़, किताबें आदि पोस्ट करने के लिए रूस में इसका तेजी से उपयोग किया जाता है। शीर्षकों, विषयों आदि के लिए एक बहुत ही सुविधाजनक खोज इंजन तक निःशुल्क पहुंच के लिए।
http://www.atlasti.com/ व्यक्तिगत उपयोगकर्ताओं, छोटे और यहां तक कि मध्यम आकार के व्यवसायों के लिए उपलब्ध गुणात्मक सूचना विश्लेषण के लिए सबसे शक्तिशाली और प्रभावी उपकरण है। कार्यक्रम बहुक्रियाशील है और इसलिए उपयोगी है। यह विभिन्न पाठ, सारणीबद्ध, ऑडियो और वीडियो फ़ाइलों के साथ-साथ गुणात्मक विश्लेषण और विज़ुअलाइज़ेशन के लिए उपकरणों के साथ काम करने के लिए एक एकीकृत सूचना वातावरण बनाने की क्षमता को जोड़ती है।
एशम्पू क्लिपफाइंडर एचडी - सूचना प्रवाह का लगातार बढ़ता हिस्सा वीडियो से आता है। तदनुसार, प्रतिस्पर्धी खुफिया अधिकारियों को ऐसे उपकरणों की आवश्यकता होती है जो उन्हें इस प्रारूप के साथ काम करने की अनुमति दें। ऐसे उत्पादों में से एक प्रस्तुत है मुफ़्त उपयोगिता. यह आपको YouTube जैसी वीडियो फ़ाइल संग्रहण साइटों पर निर्दिष्ट मानदंडों के आधार पर वीडियो खोजने की अनुमति देता है। प्रोग्राम का उपयोग करना आसान है, सभी खोज परिणाम विस्तृत जानकारी, शीर्षक, अवधि, वीडियो को स्टोरेज में अपलोड करने का समय आदि के साथ एक पृष्ठ पर प्रदर्शित करता है। एक रूसी इंटरफ़ेस है.
http://www.advego.ru/plagiatus/ - प्रोग्राम SEO ऑप्टिमाइज़र द्वारा बनाया गया था, लेकिन यह इंटरनेट इंटेलिजेंस टूल के रूप में काफी उपयुक्त है। साहित्यिक चोरी पाठ की विशिष्टता की डिग्री, पाठ के स्रोत और पाठ मिलान के प्रतिशत को दर्शाती है। प्रोग्राम निर्दिष्ट URL की विशिष्टता की भी जाँच करता है। कार्यक्रम निःशुल्क है.
http://neiron.ru/toolbar/ - संयोजन के लिए एक ऐड-ऑन शामिल है गूगल खोजऔर यांडेक्स, और साइटों और प्रासंगिक विज्ञापन की प्रभावशीलता के आकलन के आधार पर प्रतिस्पर्धी विश्लेषण की भी अनुमति देता है। एफएफ और जीसी के लिए एक प्लगइन के रूप में कार्यान्वित किया गया।
http://web-data-extractor.net/ इंटरनेट पर उपलब्ध किसी भी डेटा को प्राप्त करने के लिए एक सार्वभौमिक समाधान है। किसी भी पेज से डेटा कटिंग सेट करना कुछ ही माउस क्लिक में किया जाता है। आपको बस उस डेटा क्षेत्र का चयन करना होगा जिसे आप सहेजना चाहते हैं और डेटाकॉल स्वचालित रूप से इस ब्लॉक को काटने के लिए एक सूत्र का चयन करेगा।
कैप्चरसेवर एक पेशेवर इंटरनेट अनुसंधान उपकरण है। बस अपूरणीय कार्यशील कार्यक्रम, आपको किसी भी इंटरनेट जानकारी को कैप्चर करने, संग्रहीत करने और निर्यात करने की अनुमति देता है, जिसमें न केवल शामिल है वेब पृष्ठ, ब्लॉग, बल्कि आरएसएस समाचार, ईमेल, चित्र और भी बहुत कुछ। इसमें व्यापक कार्यक्षमता, सहज इंटरफ़ेस और हास्यास्पद कीमत है।
http://www.orbiscope.net/en/software.html - किफायती कीमतों से भी अधिक पर वेब निगरानी प्रणाली।
http://www.kbcrawl.co.uk/ - "अदृश्य इंटरनेट" सहित काम करने के लिए सॉफ्टवेयर।
http://www.copernic.com/en/products/agent/index.html - प्रोग्राम आपको 10 से अधिक मापदंडों का उपयोग करके 90 से अधिक खोज इंजनों का उपयोग करके खोज करने की अनुमति देता है। आपको परिणामों को संयोजित करने, डुप्लिकेट को हटाने, टूटे हुए लिंक को ब्लॉक करने और सबसे प्रासंगिक परिणाम दिखाने की अनुमति देता है। मुफ़्त, व्यक्तिगत और व्यावसायिक संस्करणों में आता है। 20 मिलियन से अधिक उपयोगकर्ताओं द्वारा उपयोग किया जाता है।
माल्टेगो एक मौलिक रूप से नया सॉफ्टवेयर है जो आपको वास्तविक जीवन और इंटरनेट पर विषयों, घटनाओं और वस्तुओं के बीच संबंध स्थापित करने की अनुमति देता है।
सेवा
नया - वेब ब्राउज़र OSINT के लिए दर्जनों पूर्व-स्थापित टूल के साथ।
- प्रमुख रूसी सामाजिक नेटवर्क पर लोगों को ढूंढने के लिए एक प्रभावी खोज इंजन-एग्रीगेटर।
ईमेल का पता लगाने और उसकी जांच करने के लिए https://hunter.io/ एक प्रभावी सेवा है।
https://www.whatruns.com/ - उपयोग में आसान, लेकिन कुशल स्कैनर, आपको यह पता लगाने की अनुमति देता है कि किसी वेबसाइट पर क्या काम करता है और क्या नहीं करता है और इसकी सुरक्षा खामियाँ क्या हैं। क्रोम के लिए एक प्लगइन के रूप में भी लागू किया गया।
https://www.crayon.co/ इंटरनेट पर बाजार और प्रतिस्पर्धी बुद्धिमत्ता के लिए एक अमेरिकी बजट मंच है।
http://www.cs.cornell.edu/~bwong/octant/ - होस्ट पहचानकर्ता।
https://iplogger.ru/ - किसी और का आईपी निर्धारित करने के लिए एक सरल और सुविधाजनक सेवा।
http://linkurio.us/ आर्थिक सुरक्षा कर्मियों और भ्रष्टाचार जांचकर्ताओं के लिए एक शक्तिशाली नया उत्पाद है। वित्तीय स्रोतों से बड़ी मात्रा में असंरचित जानकारी को संसाधित और विज़ुअलाइज़ करता है।
http://www.intelsuite.com/en - प्रतिस्पर्धी बुद्धिमत्ता और निगरानी के लिए अंग्रेजी भाषा का ऑनलाइन मंच।
http://yewno.com/about/ जानकारी को ज्ञान में अनुवाद करने और असंरचित जानकारी को देखने के लिए पहला ऑपरेटिंग सिस्टम है। वर्तमान में अंग्रेजी, फ्रेंच, जर्मन, स्पेनिश और पुर्तगाली का समर्थन करता है।
https://start.avalancheonline.ru/landing/?next=%2F - एंड्री मसलोविच द्वारा पूर्वानुमान और विश्लेषणात्मक सेवाएं।
https://www.outwit.com/products/hub/ - पूरा स्थिरवेब पर व्यावसायिक कार्य के लिए स्टैंड-अलोन कार्यक्रम 1.
https://github.com/search?q=user%3Acmlh+maltego - माल्टेगो के लिए एक्सटेंशन।
http://www.whoishostingthis.com/ - होस्टिंग, आईपी पते आदि के लिए खोज इंजन।
http://appfollow.ru/ - समीक्षाओं, एएसओ अनुकूलन, शीर्ष पर स्थिति और के आधार पर अनुप्रयोगों का विश्लेषण खोज के परिणामऐप स्टोर, गूगल प्ले और विंडोज फोन स्टोर के लिए आह।
http://piraldb.com/ क्रोम के लिए एक प्लगइन के रूप में कार्यान्वित एक सेवा है, जो आपको किसी भी इलेक्ट्रॉनिक संसाधन के बारे में बहुत सारी मूल्यवान जानकारी प्राप्त करने की अनुमति देती है।
https://millie.northernlight.com/dashboard.php?id=93 - नि: शुल्क सेवा, उद्योग और कंपनी द्वारा प्रमुख जानकारी एकत्र करना और संरचना करना। पाठ विश्लेषण के आधार पर सूचना पैनल का उपयोग करना संभव है।
http://byratino.info/ – से तथ्यात्मक डेटा का संग्रह सार्वजनिक रूप से उपलब्ध स्रोतइंटरनेट पर।
http://www.datafox.co/ – सीआई प्लेटफॉर्म ग्राहकों की रुचि वाली कंपनियों के बारे में जानकारी एकत्र करता है और उसका विश्लेषण करता है। एक डेमो है.
https://unwiredlabs.com/home - इंटरनेट से जुड़े किसी भी उपकरण के जियोलोकेशन द्वारा खोज के लिए एपीआई के साथ एक विशेष एप्लिकेशन।
http://visualping.io/ - साइटों और सबसे पहले, उन पर उपलब्ध तस्वीरों और छवियों की निगरानी के लिए एक सेवा। एक सेकंड के लिए भी फोटो आ जाए तो भी ईमेलग्राहक Google Chrome के लिए एक प्लगइन है.
http://spyonweb.com/ एक शोध उपकरण है जो किसी भी इंटरनेट संसाधन का गहन विश्लेषण करने की अनुमति देता है।
http://bigvisor.ru/ - सेवा आपको वस्तुओं और सेवाओं के कुछ खंडों या विशिष्ट संगठनों के लिए विज्ञापन अभियानों को ट्रैक करने की अनुमति देती है।
http://www.itsec.pro/2013/09/microsoft-word.html - आर्टेम एजेव द्वारा उपयोग के लिए निर्देश विंडोज़ प्रोग्रामप्रतिस्पर्धी खुफिया जरूरतों के लिए।
http://granoproject.org/ एक खुला स्रोत उपकरण है सोर्स कोडउन शोधकर्ताओं के लिए जो राजनीति, अर्थशास्त्र, अपराध आदि में व्यक्तियों और संगठनों के बीच संबंधों के नेटवर्क पर नज़र रखते हैं। आपको विभिन्न स्रोतों से प्राप्त जानकारी को जोड़ने, विश्लेषण करने और कल्पना करने के साथ-साथ महत्वपूर्ण कनेक्शन दिखाने की अनुमति देता है।
http://imgops.com/ - ग्राफ़िक फ़ाइलों से मेटाडेटा निकालने और उनके साथ काम करने के लिए एक सेवा।
http://sergeybelove.ru/tools/one-button-scan/ - वेबसाइटों और अन्य संसाधनों में सुरक्षा खामियों की जाँच के लिए एक छोटा ऑनलाइन स्कैनर।
http://isce-library.net/epi.aspx - पाठ के एक टुकड़े का उपयोग करके प्राथमिक स्रोतों को खोजने की सेवा अंग्रेजी भाषा
https://www.rivaliq.com/ वस्तुओं और सेवाओं के लिए पश्चिमी, मुख्य रूप से यूरोपीय और अमेरिकी बाजारों में प्रतिस्पर्धी खुफिया जानकारी संचालित करने के लिए एक प्रभावी उपकरण है।
http://watchthatpage.com/ एक ऐसी सेवा है जो आपको मॉनिटर किए गए इंटरनेट संसाधनों से स्वचालित रूप से नई जानकारी एकत्र करने की अनुमति देती है। सेवा निःशुल्क है.
http://falcon.io/ वेब के लिए एक प्रकार का Rapportive है। यह Rapportive का प्रतिस्थापन नहीं है, लेकिन अतिरिक्त उपकरण प्रदान करता है। रैपॉर्टिव के विपरीत, यह किसी व्यक्ति की सामान्य प्रोफ़ाइल देता है, जैसे कि डेटा से एक साथ चिपकाया गया हो सोशल नेटवर्कऔर web.http://watchthatpage.com/ में उल्लेख किया गया है - एक सेवा जो आपको मॉनिटर किए गए इंटरनेट संसाधनों से स्वचालित रूप से नई जानकारी एकत्र करने की अनुमति देती है। सेवा निःशुल्क है.
https://addons.mozilla.org/ru/firefox/addon/update-scanner/ - फ़ायरफ़ॉक्स के लिए ऐड-ऑन। वेब पेज अपडेट पर नज़र रखता है। उन वेबसाइटों के लिए उपयोगी जिनके पास समाचार फ़ीड (एटम या आरएसएस) नहीं है।
http://agregator.pro/ - समाचार और मीडिया पोर्टलों का एग्रीगेटर। विपणक, विश्लेषकों आदि द्वारा उपयोग किया जाता है। कुछ विषयों पर समाचार प्रवाह का विश्लेषण करना।
http://price.apishops.com/ - चयनित उत्पाद समूहों, विशिष्ट ऑनलाइन स्टोर और अन्य मापदंडों के लिए कीमतों की निगरानी के लिए स्वचालित वेब सेवा।
http://www.la0.ru/ किसी इंटरनेट संसाधन के लिंक और बैकलिंक का विश्लेषण करने के लिए एक सुविधाजनक और प्रासंगिक सेवा है।
www.recordedfuture.com डेटा विश्लेषण और विज़ुअलाइज़ेशन के लिए एक शक्तिशाली उपकरण है, जिसे क्लाउड कंप्यूटिंग पर निर्मित एक ऑनलाइन सेवा के रूप में कार्यान्वित किया गया है।
http://advse.ru/ एक सेवा है जिसका नारा है "अपने प्रतिस्पर्धियों के बारे में सब कुछ पता करें।" आपको खोज क्वेरी के अनुसार प्रतिस्पर्धियों की वेबसाइटें प्राप्त करने और Google और Yandex में प्रतिस्पर्धियों के विज्ञापन अभियानों का विश्लेषण करने की अनुमति देता है।
http://spyonweb.com/ - सेवा आपको समान विशेषताओं वाली साइटों की पहचान करने की अनुमति देती है, जिसमें समान सांख्यिकी सेवा पहचानकर्ताओं का उपयोग करने वाली साइटें भी शामिल हैं गूगल विश्लेषिकी, आईपी पते, आदि।
http://www.connotate.com/solutions - प्रतिस्पर्धी बुद्धिमत्ता, सूचना प्रवाह के प्रबंधन और सूचना को सूचना संपत्तियों में परिवर्तित करने के लिए उत्पादों की एक श्रृंखला। इसमें जटिल प्लेटफ़ॉर्म और सरल, सस्ती सेवाएँ दोनों शामिल हैं जो सूचना संपीड़न के साथ-साथ प्रभावी निगरानी और केवल आवश्यक परिणाम प्राप्त करने की अनुमति देती हैं।
http://www.clearci.com/ - स्टार्ट-अप और छोटी कंपनियों से लेकर फॉर्च्यून 500 कंपनियों तक विभिन्न आकार के व्यवसायों के लिए प्रतिस्पर्धी खुफिया मंच।
http://startingpage.com/ एक Google ऐड-ऑन है जो आपको अपना आईपी पता रिकॉर्ड किए बिना Google पर खोज करने की अनुमति देता है। रूसी सहित सभी Google खोज क्षमताओं का पूर्ण समर्थन करता है।
http://newspapermap.com/ - अद्वितीय सेवा, प्रतिस्पर्धी स्काउट के लिए बहुत उपयोगी है। जियोलोकेशन को एक ऑनलाइन मीडिया सर्च इंजन से जोड़ता है। वे। आप उस क्षेत्र का चयन करें जिसमें आपकी रुचि है, या यहां तक कि एक शहर, या भाषा, मानचित्र पर स्थान और समाचार पत्रों और पत्रिकाओं के ऑनलाइन संस्करणों की एक सूची देखें, उपयुक्त बटन पर क्लिक करें और पढ़ें। रूसी भाषा का समर्थन करता है, बहुत उपयोगकर्ता के अनुकूल इंटरफ़ेस।
http://infostream.com.ua/ एक बहुत ही सुविधाजनक समाचार निगरानी प्रणाली "इन्फोस्ट्रीम" है, जो प्रथम श्रेणी चयन द्वारा प्रतिष्ठित है और इंटरनेट खोज के क्लासिक्स में से एक, डी.वी. लैंडे से किसी भी वॉलेट के लिए काफी सुलभ है।
आवश्यक वेब पेजों को सहेजने के लिए http://www.instapaper.com/ एक बहुत ही सरल और प्रभावी उपकरण है। कंप्यूटर, आईफ़ोन, आईपैड आदि पर उपयोग किया जा सकता है।
http://screen-scraper.com/ - आपको वेब पेजों से स्वचालित रूप से सभी जानकारी निकालने, अधिकांश फ़ाइल स्वरूपों को डाउनलोड करने और स्वचालित रूप से विभिन्न रूपों में डेटा दर्ज करने की अनुमति देता है। डाउनलोड की गई फ़ाइलों और पेजों को डेटाबेस में सहेजता है, कई अन्य कार्य करता है उपयोगी कार्य. सभी प्रमुख प्लेटफार्मों पर काम करता है, इसमें पूरी तरह कार्यात्मक मुफ़्त और बहुत शक्तिशाली पेशेवर संस्करण हैं।
http://www.mozenda.com/ - कई हैं टैरिफ योजनाएंऔर चयनित साइटों से उपयोगकर्ता के लिए आवश्यक जानकारी की बहुक्रियाशील वेब निगरानी और वितरण की एक वेब सेवा, यहां तक कि छोटे व्यवसायों के लिए भी उपलब्ध है।
http://www.recipdonor.com/ - सेवा आपको प्रतिस्पर्धियों की वेबसाइटों पर होने वाली हर चीज़ की स्वचालित रूप से निगरानी करने की अनुमति देती है।
http://www.spyfu.com/ - और यह तब है जब आपके प्रतिस्पर्धी विदेशी हैं।
www.webground.su इंटरनेट खोज पेशेवरों द्वारा बनाई गई रूनेट की निगरानी के लिए एक सेवा है, जिसमें सूचना, समाचार आदि के सभी प्रमुख प्रदाता शामिल हैं, और उपयोगकर्ता की आवश्यकताओं के अनुरूप व्यक्तिगत निगरानी सेटिंग्स करने में सक्षम है।
खोज इंजन
https://www.idmarch.org/ गुणवत्ता के मामले में पीडीएफ दस्तावेज़ों के विश्व संग्रह के लिए सबसे अच्छा खोज इंजन है। वर्तमान में, 18 मिलियन से अधिक पीडीएफ दस्तावेजों को अनुक्रमित किया गया है, जिनमें किताबों से लेकर गुप्त रिपोर्ट तक शामिल हैं।
http://www.marketvisual.com/ एक अद्वितीय खोज इंजन है जो आपको मालिकों और शीर्ष प्रबंधन को पूरे नाम, कंपनी के नाम, पद या उनके संयोजन के आधार पर खोजने की अनुमति देता है। खोज परिणामों में न केवल वे वस्तुएं शामिल होती हैं जिन्हें आप ढूंढ रहे हैं, बल्कि उनके कनेक्शन भी शामिल होते हैं। मुख्य रूप से अंग्रेजी भाषी देशों के लिए डिज़ाइन किया गया।
http://worldc.am/ जियोलोकेशन से जुड़ी स्वतंत्र रूप से सुलभ तस्वीरों के लिए एक खोज इंजन है।
https://app.echosec.net/ एक सार्वजनिक खोज इंजन है जो खुद को कानून प्रवर्तन और सुरक्षा और खुफिया पेशेवरों के लिए सबसे उन्नत विश्लेषणात्मक उपकरण बताता है। आपको विशिष्ट जियोलोकेशन निर्देशांक के संबंध में विभिन्न साइटों, सोशल प्लेटफॉर्म और सोशल नेटवर्क पर पोस्ट की गई तस्वीरों को खोजने की अनुमति देता है। वर्तमान में सात डेटा स्रोत जुड़े हुए हैं। वर्ष के अंत तक उनकी संख्या 450 से अधिक हो जाएगी। टिप के लिए डिमेंटी को धन्यवाद।
http://www.quandl.com/ सात मिलियन वित्तीय, आर्थिक और सामाजिक डेटाबेस के लिए एक खोज इंजन है।
http://bitzakaz.ru/ - अतिरिक्त भुगतान कार्यों के साथ निविदाओं और सरकारी आदेशों के लिए खोज इंजन
वेबसाइट-फाइंडर - उन साइटों को ढूंढना संभव बनाता है जिन्हें Google अच्छी तरह से अनुक्रमित नहीं करता है। एकमात्र सीमा यह है कि यह प्रत्येक कीवर्ड के लिए केवल 30 वेबसाइटें खोजता है। प्रोग्राम का उपयोग करना आसान है.
http://www.dtsearch.com/ एक शक्तिशाली खोज इंजन है जो आपको टेराबाइट्स टेक्स्ट को संसाधित करने की अनुमति देता है। डेस्कटॉप, वेब और इंट्रानेट पर काम करता है। स्थिर और गतिशील डेटा दोनों का समर्थन करता है। आपको सभी MS Office प्रोग्रामों में खोज करने की अनुमति देता है। खोज वाक्यांशों, शब्दों, टैग, अनुक्रमणिका और बहुत कुछ का उपयोग करके की जाती है। एकमात्र फ़ेडरेटेड खोज इंजन उपलब्ध है. इसके पेड और फ्री दोनों वर्जन हैं।
http://www.strategator.com/ - हजारों वेब स्रोतों से कंपनी के बारे में जानकारी खोजता है, फ़िल्टर करता है और एकत्रित करता है। संयुक्त राज्य अमेरिका, ग्रेट ब्रिटेन, प्रमुख ईईसी देशों में खोजें। यह अत्यधिक प्रासंगिक, उपयोगकर्ता के अनुकूल है, और इसमें निःशुल्क और सशुल्क विकल्प ($14 प्रति माह) हैं।
http://www.shodanhq.com/ एक असामान्य खोज इंजन है। उनकी उपस्थिति के तुरंत बाद, उन्हें "हैकर्स के लिए Google" उपनाम मिला। यह पृष्ठों की खोज नहीं करता है, बल्कि किसी विशेष पते पर स्थित आईपी पते, राउटर के प्रकार, कंप्यूटर, सर्वर और वर्कस्टेशन निर्धारित करता है और श्रृंखलाओं का पता लगाता है। डीएनएस सर्वरऔर आपको प्रतिस्पर्धी बुद्धिमत्ता के लिए कई अन्य दिलचस्प कार्यों को लागू करने की अनुमति देता है।
http://search.usa.gov/ - साइटों के लिए खोज इंजन और सभी के खुले डेटाबेस सरकारी एजेंसियोंयूएसए। डेटाबेस में बहुत सारी व्यावहारिक चीजें हैं उपयोगी जानकारी, जिसमें हमारे देश में उपयोग भी शामिल है।
http://visual.ly/ - आज डेटा प्रस्तुत करने के लिए विज़ुअलाइज़ेशन का तेजी से उपयोग किया जा रहा है। यह वेब पर पहला इन्फोग्राफिक सर्च इंजन है। खोज इंजन के साथ, पोर्टल में शक्तिशाली डेटा विज़ुअलाइज़ेशन उपकरण हैं जिनके लिए प्रोग्रामिंग कौशल की आवश्यकता नहीं है।
http://go.mail.ru/realtime - वास्तविक या अनुकूलन योग्य समय में विषयों, घटनाओं, वस्तुओं, विषयों की चर्चा खोजें। Mail.ru में पहले अत्यधिक आलोचना की गई खोज बहुत प्रभावी ढंग से काम करती है और दिलचस्प, प्रासंगिक परिणाम प्रदान करती है।
ज़ैनरान अभी लॉन्च हुआ है, लेकिन पहले से ही बढ़िया काम कर रहा है, यह डेटा के लिए पहला और एकमात्र खोज इंजन है जो इसे निकालता है पीडीएफ फ़ाइलें, एक्सेल टेबल, HTML पृष्ठों पर डेटा।
http://www.ciradar.com/Competitive-Anaलिसिस.aspx डीप वेब पर प्रतिस्पर्धी इंटेलिजेंस के लिए दुनिया की सबसे अच्छी सूचना पुनर्प्राप्ति प्रणालियों में से एक है। रुचि के विषय पर सभी प्रारूपों में लगभग सभी प्रकार की फ़ाइलें पुनर्प्राप्त करता है। एक वेब सेवा के रूप में कार्यान्वित किया गया। कीमतें उचित से अधिक हैं.
http://public.ru/ - 1990 से सूचना, मीडिया संग्रह की प्रभावी खोज और पेशेवर विश्लेषण। ऑनलाइन मीडिया लाइब्रेरी सूचना सेवाओं की एक विस्तृत श्रृंखला प्रदान करती है: रूसी भाषा के मीडिया प्रकाशनों के इलेक्ट्रॉनिक अभिलेखागार तक पहुंच और तैयार विषयगत प्रेस समीक्षाओं से लेकर व्यक्तिगत निगरानी और प्रेस सामग्री पर आधारित विशेष विश्लेषणात्मक अनुसंधान तक।
क्लुज़ एक युवा खोज इंजन है जिसमें प्रतिस्पर्धी बुद्धिमत्ता के लिए पर्याप्त अवसर हैं, खासकर अंग्रेजी भाषा के इंटरनेट पर। आपको न केवल खोजने, बल्कि लोगों, कंपनियों, डोमेन, ई-मेल, पते आदि के बीच कनेक्शन की कल्पना करने और स्थापित करने की भी अनुमति देता है।
www.wolframalpha.com - कल का खोज इंजन। पर प्रश्न खोजनाविज़ुअलाइज़ की गई जानकारी सहित अनुरोध ऑब्जेक्ट पर उपलब्ध सांख्यिकीय और तथ्यात्मक जानकारी प्रदर्शित करता है।
www.ist-budget.ru - सरकारी खरीद, निविदाओं, नीलामी आदि के डेटाबेस में सार्वभौमिक खोज।
हमारे समय में किस बारे में बात करें सूचना प्रौद्योगिकीऔर व्यक्ति और समाज दोनों के लिए उपलब्ध डेटा की मात्रा में अंतहीन वृद्धि, जानकारी को संसाधित करने और उसकी खोज करने में कई समस्याएं हैं - यह पहले से ही ईशनिंदा है। यह विषय कौन नहीं उठाता? और समस्या के संबंध में विभिन्न सूचना स्रोतों से लिए गए व्यक्तिपरक और आंशिक रूप से वस्तुनिष्ठ निर्णयों का बोझ आप पर न डालने के लिए, मैं सीधे इसके समाधान की ओर बढ़ूंगा। आज हम खोज के बारे में बात करेंगे. अर्थात्, प्रोग्रामों और गंभीर सूचना प्रणालियों के बारे में जो हमारे लिए आवश्यक दस्तावेज़ों और डेटा की खोज करते हैं।
"प्रत्यक्ष खोज" को अपग्रेड करें
बहुत समय पहले की बात नहीं है, जब पेड़ बड़े थे, और जानकारी भी बहुत बड़ी थी स्थानीय नेटवर्कइतने सारे उद्यम नहीं थे, कोई भी खोज मुट्ठी भर उपलब्ध फाइलों की साधारण खोज और उनके नामों और सामग्रियों की क्रमिक जांच के द्वारा की जाती थी। ऐसी खोज को प्रत्यक्ष कहा जाता है, और प्रत्यक्ष खोज तकनीक का उपयोग करने वाले कार्यक्रम (उपयोगिताएँ) पारंपरिक रूप से सभी में मौजूद हैं ऑपरेटिंग सिस्टमऔर टूल पैकेज। लेकिन फिर भी शक्ति आधुनिक कंप्यूटरप्रत्यक्ष खोज के दौरान डेटा की विशाल मात्रा में त्वरित और पर्याप्त खोज के लिए पर्याप्त नहीं है। एक डिस्क पर कुछ सौ दस्तावेज़ों को खोजना और एक विशाल लाइब्रेरी और कई दर्जन मेलबॉक्सों को खोजना दो अलग-अलग चीज़ें हैं। इसलिए, जब सार्वभौमिक उपकरणों की बात आती है, तो आज प्रत्यक्ष खोज कार्यक्रम स्पष्ट रूप से पृष्ठभूमि में लुप्त होते जा रहे हैं।
बेशक, कॉर्पोरेट क्षेत्र में इस प्रकार की खोज की लंबे समय से मांग नहीं रही है। वॉल्यूम समान नहीं हैं. और इसलिए, अब कई वर्षों से, और आगे भी हाल ही मेंनिश्चित रूप से, प्रौद्योगिकियां तेजी से कार्यान्वित करने में सक्षम हैं सटीक खोजविभिन्न प्रारूपों और विभिन्न स्रोतों से प्राप्त दस्तावेज़ प्रासंगिक से अधिक हैं। अभी कुछ समय पहले, माइक्रोसॉफ्ट के "पिता" बिल गेट्स ने, जाहिर तौर पर इंटरनेट सर्च इंजन गूगल की अभूतपूर्व सफलता से ईर्ष्या करते हुए, एक प्रेस कॉन्फ्रेंस में सॉफ्टवेयर उद्योग (और न केवल) की हर संभव तरीके से योगदान करने की इच्छा की घोषणा की, खोज इंजनों और प्रौद्योगिकियों के निर्माण को विकसित और गहन बनाना। लेकिन माइक्रोसॉफ्ट या इंटरनेट पर प्रतिस्पर्धी सर्वर (एमएसएन अभी भी Google तक नहीं पहुंच पाया है) से कोई भी असाधारण कार्यशील प्रोग्राम बनाना जल्दबाजी होगी। इसलिए, आइए मौजूदा विकास की ओर मुड़ें। सूचकांक, क्वेरी, प्रासंगिकता
आधुनिक प्रौद्योगिकियाँ दो मूलभूत प्रक्रियाओं पर आधारित हैं। सबसे पहले, यह उपलब्ध जानकारी को अनुक्रमित कर रहा है और परिणामों के बाद के आउटपुट के साथ अनुरोध को संसाधित कर रहा है। पहले के लिए, कोई भी प्रोग्राम (चाहे वह डेस्कटॉप सर्च इंजन हो, कॉर्पोरेट सूचना प्रणालीया इंटरनेट सर्च इंजन) अपना स्वयं का खोज क्षेत्र बनाता है। अर्थात्, यह दस्तावेज़ों को संसाधित करता है और इन दस्तावेज़ों का एक सूचकांक (एक संगठित संरचना जिसमें संसाधित डेटा के बारे में जानकारी होती है) उत्पन्न करता है। भविष्य में, यह बनाया गया सूचकांक है जिसका उपयोग काम के लिए किया जाता है - अनुरोध के अनुसार आवश्यक दस्तावेजों की एक सूची जल्दी से प्राप्त करना। इसके बाद जो कुछ भी है, वह प्रौद्योगिकी के मामले में किसी भी तरह से सरल नहीं है, फिर भी काफी समझने योग्य है औसत उपयोगकर्ता के लिए. प्रोग्राम अनुरोध को संसाधित करता है (कीवर्ड वाक्यांश का उपयोग करके) और उन दस्तावेज़ों की एक सूची प्रदर्शित करता है जिनमें यह कीवर्ड वाक्यांश होता है। चूंकि जानकारी एक संरचित सूचकांक में निहित है, इसलिए प्रत्यक्ष खोज के मामले की तुलना में क्वेरी प्रोसेसिंग बहुत तेज (दसियों और सैकड़ों गुना!) होती है (दस्तावेजों का चयन फाइलों की गणना करके नहीं, बल्कि पाठ जानकारी का विश्लेषण करके किया जाता है)। अनुक्रमणिका)।
प्रोग्राम प्रासंगिकता के अनुसार परिणामी सूची में पाए गए दस्तावेज़ों को प्रदर्शित करता है - क्वेरी पाठ के साथ दस्तावेज़ का अनुपालन। विभिन्न तकनीकों में, निश्चित रूप से, किसी दस्तावेज़ की प्रासंगिकता को खोजने और निर्धारित करने के लिए अलग-अलग तरीके हैं (किसी शब्द की "घटनाओं" की संख्या और दस्तावेज़ में इसके उल्लेख की आवृत्ति, इन मापदंडों का शब्दों की कुल संख्या से अनुपात) दस्तावेज़ में, खोजी गई फ़ाइलों में क्वेरी वाक्यांश के शब्दों के बीच की दूरी, इत्यादि)। इन मापदंडों के आधार पर, दस्तावेज़ का "वजन" निर्धारित किया जाता है और, इसके आधार पर, एक विशेष फ़ाइल एक निश्चित स्थान पर परिणामों की सूची में दिखाई देती है। इंटरनेट खोज के मामले में स्थिति और भी जटिल है। दरअसल, इस मामले में, कई अन्य कारकों को ध्यान में रखा जाना चाहिए (Google का पेज रैंक इसका एक उदाहरण है)। लेकिन यह एक अलग लेख का विषय है, इसलिए हम इंटरनेट की समीक्षा पर ध्यान नहीं देंगे
यह सामग्री कई संभावनाओं पर चर्चा करती है लोकप्रिय कार्यक्रमखोज इंजन, जो अच्छी गति और अच्छी कार्यक्षमता दोनों का दावा करते हैं। लेकिन ब्रोशर में दिखावा करना एक बात है, लेकिन किसी विशेषज्ञ की निगाह में खड़े रहना बिल्कुल दूसरी बात है। और वहाँ न तो अधिक विशेषज्ञ थे, न ही ऐसे लोगों से भरा कार्यालय जो इसकी उपयोगिता के लिए सॉफ़्टवेयर के साथ छेड़छाड़ करना पसंद करते थे। एक प्रायोगिक कंप्यूटर पर (एथलॉन 2.2 मेगाहर्ट्ज, क्षमता के साथ)। रैंडम एक्सेस मेमोरी 1 जीबी, 160 जीबी सीगेट 7200 आरपीएम आईडीई हार्ड ड्राइव और विंडोज़ सिस्टम XP) प्रोग्रामों का एक सेट स्थापित किया गया था: dtSearch डेस्कटॉप, ब्लडहाउंड प्रोफेसर डिलक्स, Google डेस्कटॉप सर्च, सर्चइनफॉर्म, कॉपरनिक डेस्कटॉप सर्च, ISYS डेस्कटॉप। परीक्षणों के लिए, दस्तावेजों का एक टेक्स्ट डेटाबेस doc, txt और html प्रारूपों में संकलित किया गया था, जिसका कुल आकार न तो अधिक और न ही कम था, बल्कि 20 गीगाबाइट था। आपके विनम्र सेवक के नेतृत्व में साथियों के एक समूह ने प्रत्येक सॉफ़्टवेयर का परीक्षण, तुलना और अपने व्यक्तिपरक प्रभाव साझा किए। नीचे निष्कर्षों का सारांश पढ़ें। डीटीसर्च डेस्कटॉप
एक प्रोग्राम, जो डेवलपर्स के अनुसार, सबसे तेज़, सबसे सुविधाजनक और सर्वोत्तम खोज इंजन होने का दावा करता है। सामान्य तौर पर, इस समीक्षा से बाकी सभी लोग। DtSearch इंटरफ़ेस काफी सरल है, लेकिन कुछ विंडोज़ या टैब तत्वों से कुछ हद तक अतिभारित हैं, जिससे इसका उपयोग करना मुश्किल लगता है। लेकिन हकीकत में कोई खास मुश्किलें नहीं हैं. एकमात्र वास्तव में अप्रिय बिंदु सॉफ़्टवेयर में रूसी भाषा के लिए समर्थन की कमी है (इस तथ्य के बावजूद कि प्रोग्राम कई भाषाओं में दस्तावेज़ खोज सकता है, इसका इंटरफ़ेस विशेष रूप से अंग्रेजी है)।
लेकिन dtSearch उन कुछ कार्यक्रमों में से एक है जो वेब पेजों को उपयोगकर्ता द्वारा निर्दिष्ट "गहराई" पर अनुक्रमित कर सकता है (यद्यपि, dtSearch स्पाइडर ऐड-ऑन किट की "अतिरिक्त खरीद" को ध्यान में रखते हुए)। यह विभिन्न डिस्क पर फ़ाइलों का समर्थन करने के अतिरिक्त है पाठ प्रारूपऔर से ईमेल मेलबॉक्सआउटलुक। साथ ही, प्रोग्राम डेटाबेस के साथ काम नहीं कर सकता है, जो उनमें मौजूद बड़ी मात्रा में जानकारी और कंपनियों में उनके व्यापक वितरण और इसलिए कॉर्पोरेट नेटवर्क में उनके व्यापक वितरण के कारण खोज इंजन के लिए इतना स्वादिष्ट निवाला है। dtSearch दस्तावेज़ों को अनुक्रमित करने की गति उचित स्तर पर निकली। आगे देखते हुए, मैं कहूंगा कि इस कार्यक्रम ने एक अन्य प्रतियोगी - iSYS - के साथ एक स्तर पर दी गई जानकारी की अनुक्रमणिका का मुकाबला किया और इसके साथ सबसे अधिक की सूची में दूसरा स्थान साझा किया। तेज़ सिस्टम. dtSearch ने 6 घंटे और 13 मिनट में एक परीक्षण में 20 गीगाबाइट जानकारी को अनुक्रमित किया, जिससे बाद की खोज आवश्यकताओं के लिए 7.9 जीबी का एक सूचकांक तैयार हुआ।
जहाँ तक खोज क्षमताओं का प्रश्न है, यहाँ वे उचित स्तर पर हैं। सबसे पहले, dtSearch में एक रूपात्मक खोज होती है (किसी शब्द को उसके सभी रूपात्मक रूपों में खोजना)। का उपयोग करते हुए अवसर, आप अपने आप को इस तरह के विचारों से मुक्त करते हैं, जैसे "किस मामले में मुझे जिस दस्तावेज़ की आवश्यकता थी उसमें एक निश्चित शब्द का उपयोग किया गया था?" रूपात्मक खोज का उपयोग लगभग हमेशा उचित होता है, इसलिए इसे किसी भी पेशेवर खोज इंजन में मौजूद होना चाहिए।
पेशेवर खोज इंजनों के लिए भी ध्वनि द्वारा खोज एक गैर-मानक सुविधा है। इसका सार यह है कि प्रोग्राम उन शब्दों की खोज करेगा जो आपके द्वारा दर्ज किए गए शब्द के समान लगते हैं। और सबसे अच्छी बात यह है कि यह फ़ंक्शन रूसी भाषा के लिए भी काम करता है! उदाहरण के लिए, जब आप किसी खोज क्वेरी में "कान" शब्द टाइप करते हैं, तो आपको परिणाम के रूप में न केवल "कान" शब्द बल्कि "कान" भी दिखाई देगा।
त्रुटि सुधार के साथ खोज एक बहुत ही महत्वपूर्ण कार्य है। इसका उपयोग वाक्यात्मक त्रुटियों वाले शब्दों को खोजने के लिए किया जाता है - ये या तो टाइपो हो सकते हैं या उदाहरण के लिए, चरित्र पहचान प्रणालियों का उपयोग करके प्राप्त दस्तावेजों में त्रुटियां हो सकती हैं। एक सरल उदाहरण - आप कीबोर्ड शब्द ढूंढ रहे हैं। कुछ दस्तावेज़ में "कीबोर्ड" शब्द शामिल है, यह स्पष्ट है कि वास्तव में यह "कीबोर्ड" शब्द है, व्यक्ति ने टाइप करते समय बस एक टाइपो बनाया है। तो, एक त्रुटि सुधार खोज परिणाम में "कीबोर्ड" शब्द के साथ एक दस्तावेज़ का पता लगाएगी और उसे शामिल करेगी। DtSearch में एक सेटिंग भी है जो आपको संभावित गलत वर्णों की डिग्री निर्धारित करने की अनुमति देती है।
समानार्थक शब्द का उपयोग करके खोजें। यह सुविधा विभिन्न शब्दों के लिए समानार्थक शब्दों की सूची का उपयोग करती है। इसलिए, उदाहरण के लिए, "फास्ट" शब्द दर्ज करने पर, प्रोग्राम को "हाई-स्पीड" और अन्य शब्द भी मिलेंगे जो "फास्ट" शब्द के पर्यायवाची हैं, यदि, निश्चित रूप से, वे समानार्थक शब्द की सूची में मौजूद हैं . dtSearch प्रोग्राम के साथ पर्यायवाची शब्दों की तैयार सूची प्रदान नहीं की जाती है, हालाँकि, इंटरनेट पर सूचियों का उपयोग करना संभव है (तदनुसार, एक कनेक्शन की आवश्यकता होती है, जो हमेशा सुविधाजनक नहीं होता है), या आप पर्यायवाची शब्दों की अपनी सूची बना सकते हैं .
सूचीबद्ध क्षमताओं के अलावा, dtSearch तार्किक संचालन से जुड़े शब्दों से युक्त वाक्यांशों का उपयोग करके खोज कर सकता है। किसी प्रश्न में प्रत्येक शब्द को अपना "वजन" यानी महत्व सौंपा जा सकता है। एक उपयोगी विकल्प एक शब्दकोश का उपयोग करना है जिसमें शामिल है सार्थक शब्दहालाँकि, खोज करते समय उन्हें ध्यान में न रखने के लिए, यह शब्दकोश भी खाली है और आपको इसे स्वयं भरना होगा।
आगे, आइए नेटवर्क पर काम करते समय प्रोग्राम की क्षमताओं को देखें। वास्तव में, dtSearch नेटवर्क के साथ काम करने के लिए कोई विशिष्ट क्षमताएं प्रदान नहीं करता है। हालाँकि, इसे ऑनलाइन उपयोग करना काफी संभव है। वैकल्पिक रूप से, आप किसी प्रकार का इंडेक्स बना सकते हैं और उसे सार्वजनिक (साझा) फ़ोल्डर में डाल सकते हैं। प्रोग्राम स्वयं प्रत्येक उपयोगकर्ता के कंप्यूटर पर स्थापित किया जा सकता है, या इसे खुले फ़ोल्डर में भी रखा जा सकता है सार्वजनिक अभिगम, और पैरामीटर का उपयोग करके प्रत्येक उपयोगकर्ता के लिए अलग से विशेष शॉर्टकट बनाएं कमांड लाइन, जिसका उद्देश्य प्रोग्राम के साथ प्रदान की गई सहायता फ़ाइल में वर्णित है। इसकी भी संभावना है स्वचालित स्थापनानेटवर्क का उपयोग करने के लिए प्रोग्राम एमएसआई फ़ाइल. यह प्रत्येक कनेक्टेड उपयोगकर्ता के लिए सेटिंग्स को ध्यान में रखेगा।
सामान्य तौर पर, यह पेशेवर खोज इंजनों की श्रेणी से एक अच्छा कार्यक्रम है। यह एक अच्छी रेटिंग के लिए अर्हता प्राप्त कर सकता है, लेकिन कुछ कारकों के कारण dtSearch के लिए उपयोगकर्ताओं से विश्वास और सम्मान प्राप्त करना आसान नहीं हो सकता है (इंटरफ़ेस के साथ सब कुछ सुचारू नहीं है, रूसी उपयोगकर्ता वंचित हैं, नेटवर्क के साथ काम करने के लिए कोई उज्ज्वल सुविधाएँ नहीं हैं) . जहाँ तक दस्तावेज़ों की सीधे खोज की बात है, कार्यक्रम में रूसी पाठ के साथ कोई समस्या नहीं थी। चूंकि घोषित आकृति विज्ञान, या अस्पष्ट खोज के साथ कोई नहीं था। सिस्टम ने एक साधारण एक-शब्द क्वेरी और कुछ पैराग्राफ या दस्तावेज़ को मुख्य वाक्यांश के रूप में उपयोग करके पर्याप्त रूप से आवश्यक दस्तावेज़ ढूंढ लिए।
आधिकारिक साइट:
वितरण का आकार: 23 एमबी ब्लडहाउंड प्रो डीलक्स
नाम के आधार पर आप अंदाजा लगा सकते हैं कि इस प्रोग्राम में रूसी भाषा के लिए सपोर्ट मौजूद है। यह पहले से ही अच्छा है. इंटरफ़ेस के लिए, सामान्य तौर पर, यह कुछ हद तक असामान्य है, लेकिन दिखने में यह बहुत आकर्षक है। दूसरी चीज़ है सुविधा. एक बहुत ही विवादास्पद मानदंड, लेकिन फिर भी, शायद, एक मल्टी-विंडो समाधान सबसे सफल विकल्प नहीं है (अनुरोध एक विंडो में दर्ज किया जाता है, परिणाम दूसरे में प्रदर्शित होता है, और इसी तरह)।
स्नूप त्वरित खोज करने के लिए समान इंडेक्स का उपयोग करता है, लेकिन इंडेक्सिंग अन्य प्रोग्रामों की तुलना में बहुत धीमी है। यह बहुत अजीब है, विशेष रूप से यह देखते हुए कि खोज क्वेरी को संसाधित करने की इसकी क्षमताएं बहुत कमजोर हैं, और इसलिए सूचकांक संरचना जटिल नहीं है। सबसे अधिक संभावना है, यह अअनुकूलित एल्गोरिदम के कारण है। यह प्रोग्राम अनुक्रमणिका और खोज गति में स्पष्ट रूप से बाहरी व्यक्ति साबित हुआ: एक सूचकांक बनाने में लगने वाला समय dtSearch और iSYS की तुलना में छह गुना अधिक है। ब्लडहाउंड के लिए 20 गीगाबाइट टेक्स्ट को अनुक्रमित करने में 38 घंटे और 46 मिनट का काम लगा। और निर्मित "खोज क्षेत्र" ने हार्ड ड्राइव पर मूल डेटा के समान आकार लिया, एक छोटे से माइनस - 19 गीगाबाइट के साथ।
ब्लडहाउंड को विंडोज़ में मानक खोज के विकल्प के रूप में प्रस्तुत किया जा सकता है; यह अधिक सक्षम होने की संभावना नहीं है। यह तथ्य कि स्नूपर का प्राथमिक कार्य फ़ाइलों की सबसे सरल खोज है, न केवल खोज क्वेरी के पाठ का विश्लेषण करने के लिए कार्यों की छोटी संख्या और फ़ाइल विशेषताओं द्वारा उन्नत खोज से संकेत मिलता है, बल्कि परिणाम विंडो से भी पता चलता है जो सीधे लिंक प्रदान करता है फ़ाइलें मिलीं, साथ ही उन फ़ोल्डरों की भी जिनमें ये फ़ाइलें हैं। परिणाम विंडो इस अर्थ में बहुत जानकारीपूर्ण नहीं है कि आप पूरी मिली फ़ाइल को केवल चलाकर ही पढ़ सकते हैं, अर्थात इसमें अंतर्निहित फ़ाइल व्यूअर नहीं है। लेकिन फ़ाइल का एक अंश जहां खोजा गया शब्द पाया गया था, सामान्य तौर पर प्रदर्शित होता है, यह प्रदर्शन योजना इंटरनेट खोज इंजन की बहुत याद दिलाती है।
खोज क्वेरी को संसाधित करने के लिए विशिष्ट क्षमताओं के बारे में बोलते हुए, यह ध्यान देने योग्य है कि "खोज पाठ" जैसी कोई चीज़ नहीं है जिसे खोजा जा सकता है वह एक वाक्यांश है, यदि केवल इसलिए कि कोई बहु-पंक्ति पाठ इनपुट फ़ील्ड नहीं है; हालाँकि, आप दर्ज किए गए वाक्यांश का विश्लेषण भी कर सकते हैं, और स्नूप हमें यहां एक मानक खोज सेट प्रदान करता है: तार्किक संचालन, मुखौटा खोज और उद्धरण खोज... बहुत कुछ नहीं। कार्यक्रम में रूपात्मक खोज की कुछ बुनियादी बातें शामिल हैं, लेकिन शायद इतनी अपरिष्कृत कि यह हस्तक्षेप करती है सही संचालन(परीक्षण के दौरान, आकृति विज्ञान के गलत उपयोग के साथ कई ओवरले देखे गए)।
लेकिन प्रोग्राम आपको खोजते समय फ़ाइल विशेषताएँ निर्दिष्ट करने की अनुमति देता है (दस्तावेज़ दिनांक, फ़ाइल नाम, फ़ोल्डर नाम), और इन प्रश्नों में आप उसी खोज सेट का भी उपयोग कर सकते हैं। आप पैरामीटर (प्रेषक, विषय..., आदि) निर्दिष्ट करके भी अक्षरों को खोज सकते हैं।
इसलिए, हमने खोज से ही पता लगा लिया कि आधिकारिक वेबसाइट से मिली जानकारी के अनुसार, कार्यक्रम के बारे में और क्या दिलचस्प है, जिसके लिए इसे इतने सारे पुरस्कार मिले? यह कहना मुश्किल है कि इसमें क्या खास है; सबसे अधिक संभावना है, ब्लडहाउंड इंटरफ़ेस आकर्षक है (बिल्कुल दिखने में, प्रयोज्य का उल्लेख नहीं है)।
इंडेक्स के साथ संचालन बहुत मानक हैं; एक अच्छी सुविधा एक शेड्यूल पर इंडेक्स को अपडेट करने की क्षमता है। इसके अतिरिक्त, इंडेक्स का उपयोग ऑनलाइन भी किया जा सकता है। अब से हमें और अधिक विवरणों की आवश्यकता है।
खोज क्वेरी की प्रधानता के बावजूद, प्रोग्राम का उपयोग फ़ाइलों को खोजने के लिए किया जा सकता है, इसलिए नेटवर्क में इसका उपयोग उचित ठहराया जा सकता है। हालाँकि यह एक खिंचाव है, क्योंकि एक बड़े नेटवर्क में प्राथमिकता बड़ी मात्रा में जानकारी के कारण जटिल खोज क्वेरी का उपयोग करके डेटा को जल्दी से खोजना है - और खोज की गति और कार्यक्रम के साथ स्पष्ट रूप से समस्याएं हैं। मुझे कहना होगा कि इज़िशिका में नेटवर्क के साथ काम उसी तरह सोचा जाता है जैसा उसे करना चाहिए। इसके लिए विशेष रूप से एक अलग एप्लिकेशन डिज़ाइन किया गया है - ब्लडहाउंड सर्वर। यह स्नूपर की तरह ही काम करता है (उनके पास एक ही खोज इंजन है), केवल केंद्रीय सर्वर पर या साझा संसाधनों पर होस्ट किए गए दस्तावेज़ों के लिए कॉर्पोरेट नेटवर्क. स्नूपर सर्वर साझा संसाधनों पर नए इंडेक्स बनाता है या पहले बनाए गए इंडेक्स का उपयोग करता है। कॉर्पोरेट नेटवर्क का कोई भी उपयोगकर्ता खोज सर्वर से जुड़ सकता है और इंटरनेट ब्राउज़र का उपयोग करके किसी भी दस्तावेज़ (वर्तमान सूचकांक में स्थित) तक पहुंचने के लिए इसका उपयोग कर सकता है। सहमत हूँ, यह योजना बेहद सुविधाजनक है: यह पता चलता है कि आपके अपने नेटवर्क पर फ़ाइलें उसी तरह से खोजी जा सकती हैं जैसे इंटरनेट पर जानकारी, उदाहरण के लिए, Google के माध्यम से।
इस कार्यक्रम के सभी फायदे और नुकसान का आकलन करते हुए, निष्कर्ष से पता चलता है कि इसकी क्षमताएं कॉर्पोरेट नेटवर्क (नेटवर्क के साथ काम करने के अच्छे संगठन के बावजूद) के लिए पर्याप्त नहीं हैं, लेकिन घरेलू कंप्यूटर या यहां तक कि घरेलू नेटवर्क के लिए भी यह पर्याप्त है। , सिद्धांत रूप में, यह सामने आ सकता है। हालाँकि न तो काम की गति और न ही खोज क्षमताएँ आशावाद को प्रेरित करती हैं...
रूसी में आधिकारिक वेबसाइट:
वितरण आकार: 6 एमबीगूगल डेस्कटॉप सर्च + जीडीएस एंटरप्राइज 
निःसंदेह, हम ऐसे प्रसिद्ध डेवलपर को नज़रअंदाज़ नहीं कर सकते। नाम Google पहले से हीबहुत कुछ कहता है. जो लोग वर्षों से सबसे शक्तिशाली इंटरनेट खोज इंजन का उपयोग कर रहे हैं, वे निश्चित रूप से, बिना किसी संदेह के, इस विशेष खोज इंजन को अपने कंप्यूटर पर स्थापित करने का निर्णय लेंगे। ज़रा सोचिए: आपके घरेलू कंप्यूटर पर Google! हालाँकि, व्यापक रूप से प्रचारित ब्रांड के उकसावे में आए बिना, आइए Google के "डेस्कटॉप" खोज इंजन की क्षमताओं पर गंभीरता से और सबसे महत्वपूर्ण रूप से निष्पक्षता से विचार करने का प्रयास करें।
पहली चीज़ जो आपका ध्यान खींचती है वह प्रोग्राम के लिए अपने स्वयं के शेल की कमी है। Google डेस्कटॉप खोज अभी भी ब्राउज़र विंडो में स्थित है, डेस्कटॉप संस्करण का संपूर्ण इंटरफ़ेस उसके पुराने इंटरनेट भाई के सॉफ़्टवेयर से विरासत में मिला था। यह अच्छा है या बुरा यह एक विवादास्पद मुद्दा है: कुछ लोगों को इस खोज इंजन के डिज़ाइन में अतिसूक्ष्मवाद पसंद है, जबकि अन्य सभी प्रकार के बटनों आदि से भरा एक पूर्ण एप्लिकेशन देखना चाहते हैं।
डिज़ाइन के ठीक बाद आपका ध्यान किस ओर आकर्षित होता है? और तथ्य यह है कि यही Google डेस्कटॉप खोज, बिना किसी मांग के, कंप्यूटर पर हर चीज़ को अनुक्रमित करना शुरू कर देती है! और सबसे दिलचस्प बात यह है कि कब अनुक्रमण पथ चुनना है गूगल सहायताडेस्कटॉप खोज संभव नहीं है. आपको एक अलग प्रोग्राम (TweakGDS) डाउनलोड करना होगा, जो आपको थोड़ा विस्तार करने की अनुमति देगा गूगल सेटिंग्सडेस्कटॉप, जिसमें अनुक्रमण के लिए आवश्यक स्थानों को निर्दिष्ट करना शामिल है। हालाँकि, जब तक आप यह सब समझेंगे, यह पहले से ही एक मानक हार्ड ड्राइव को अनुक्रमित कर देगा, इसलिए बड़ी मात्रा में डेटा के साथ काम करते समय इस सेटिंग की आवश्यकता होने की अधिक संभावना है, जो कॉर्पोरेट नेटवर्क (एंटरप्राइज़ संस्करण) में उपयोग किए जाने पर बहुत महत्वपूर्ण है। . हालाँकि, यह सच नहीं है कि TweakGDS डाउनलोड करने के बाद आपकी समस्याएँ हल हो जाएँगी। आख़िरकार, उसे काम करने के लिए Microsoft की ज़रूरत है। शुद्ध रूपरेखाऔर माइक्रोसॉफ्ट स्क्रिप्टिंग रनटाइम। हाँ... इंस्टॉलेशन, साथ ही सेटिंग्स तक पहुंच को सरल बनाया जा सकता था, हालांकि डेवलपर्स शायद समझ सकते हैं: जब एक तैयार खोज इंजन है तो कुछ नया क्यों लिखें, इसे स्थानीय कंप्यूटर पर पोर्ट करें और जाने दें उपयोगकर्ता "आनंद लें", और एक प्रसिद्ध नाम "इससे" एक और उत्कृष्ट कृति बना देगा। आइए, इस गीतात्मक विषयांतर को समाप्त करें और खोज की ओर बढ़ें।
जहाँ तक खोज क्वेरी का विश्लेषण करने और परिणाम देने की बात है, यहाँ सब कुछ बिल्कुल इंटरनेट पर Google के समान है: परिणाम प्रदर्शित करने के लिए समान प्रणाली, खोज क्वेरी के लिए तार्किक संचालन का समान मानक सेट। सामान्य तौर पर, Google डेस्कटॉप खोज, पिछले प्रोग्राम की तरह, विशेष रूप से फ़ाइलों की खोज के लिए है - निस्संदेह, इसमें इन फ़ाइलों के लिए कोई आंतरिक व्यूअर नहीं है। Google डेस्कटॉप खोज द्वारा समर्थित फ़ाइल स्वरूपों की संख्या काफी है, और यह भी अच्छा है कि यह कैश से डेटा लेकर विज़िट किए गए इंटरनेट पृष्ठों की खोज करता है। खोज और अनुक्रमण गति काफी स्वीकार्य हैं। सच है, के लिए घरेलू इस्तेमाल. Google डेस्कटॉप खोज ने 8 घंटे और 17 मिनट में प्रभावशाली 20 गीगाबाइट टेक्स्ट का प्रबंधन किया। किसी बड़े उद्यम के कॉर्पोरेट नेटवर्क से जानकारी संसाधित करने में कई दिन खर्च करना कोई ऐसी चीज़ नहीं है जो कोई भी सिस्टम प्रशासक करना चाहेगा। अच्छी बात यह है कि निर्मित सूचकांक का आकार इस समीक्षा में परीक्षण किए गए एक अन्य खोज इंजन - सर्चइनफॉर्म के समान स्तर (4.5 जीबी) पर था।
Google डेस्कटॉप खोज का बड़ा लाभ (या नुकसान - आप तय करें) यह है कि यह प्लगइन्स का समर्थन करता है, जो बेहतरी के लिए बहुत कुछ बदल सकता है। एक और बात यह है कि प्लगइन्स को कनेक्ट करना और उन्हें सेट करना एक खोज इंजन को स्थापित करने के कार्य को इतना जटिल बना देता है कि आप आश्चर्यचकित होने लगते हैं कि क्या यह सब आवश्यक है जब आप एक सामान्य, पूर्ण प्रोग्राम इंस्टॉल कर सकते हैं जिसमें सब कुछ पहले से मौजूद होगा। आख़िरकार, प्रत्येक सुविधा का उपयोग करने के लिए आपको इंस्टॉल करना होगा नया प्लगइन. यहां तक कि कार्यक्रम को अभिलेखागार के साथ पूरी तरह से काम करने के लिए एक अलग गैजेट की आवश्यकता होती है। यह आकर्षक और आकर्षक है कि ये सभी अतिरिक्त मॉड्यूल निःशुल्क हैं। हालाँकि, यदि आप खोज इंजन के डेस्कटॉप संस्करण को ध्यान में नहीं रखते हैं, तो जीडीएस एंटरप्राइज का सक्षम कॉन्फ़िगरेशन आपके अधिकार में नहीं हो सकता है - आखिरकार, यह कुछ भी नहीं है कि Google के विशेषज्ञ अपनी स्वयं की स्थापना के लिए अपनी सेवाएं प्रदान करते हैं सॉफ़्टवेयरआपके नेटवर्क के लिए केवल $10,000 में।
यदि आप सेटअप और इंस्टॉलेशन प्रक्रिया से गुजरते हैं (या Google की त्वरित प्रतिक्रिया टीम को $10,000 का भुगतान करते हैं), तो आप समझेंगे कि कॉर्पोरेट नेटवर्क में उपयोग किए जाने पर इंस्टॉलेशन की जटिलता की भरपाई बहुत लचीली सेटिंग्स से होती है। कॉर्पोरेट नेटवर्क पर Google डेस्कटॉप का उपयोग करना एक महत्वपूर्ण पहलू है समूह नीतियां, जो प्रत्येक उपयोगकर्ता के लिए सेटिंग्स सेट करना संभव बनाता है।
संक्षेप में कहें तो, इस प्रोग्राम के लिए सबसे उचित उपयोग घर या कार्यस्थल का कंप्यूटर है। आख़िरकार, के लिए नियमित कंप्यूटरआपको बस प्रोग्राम इंस्टॉल करने की आवश्यकता है - यह बाकी काम स्वयं कर लेगा (यह आपसे कुछ भी नहीं पूछेगा)।
हालाँकि, Google डेस्कटॉप सर्च एंटरप्राइज उन मामलों में स्वीकार्य होगा जहां खोज इंजन का उपयोग करने के लिए नेटवर्क नीति के लचीले कॉन्फ़िगरेशन की तत्काल आवश्यकता है, जबकि खोज प्रश्नों को संसाधित करने की क्षमता महत्व में दूसरे स्थान पर होगी, और समय (या पैसा) ) कार्यक्रम की स्थापना पर खर्च प्रथम स्थान पर होगा।
आधिकारिक साइट:
TweakGDS सहित वितरण आकार: 1.2 एमबी कॉपरनिक डेस्कटॉप खोज 
विस्तार करने के लिए तस्वीर पर क्लिक करें
प्रोग्राम इंटरफ़ेस अत्यंत सकारात्मक भावनाओं को उद्घाटित करता है - सब कुछ आम तौर पर स्वीकृत मानकों के अनुसार किया जाता है, कुछ भी अतिश्योक्तिपूर्ण नहीं, एक शब्द में, एक सुखद डिज़ाइन। एक शुरुआत के लिए, कॉपरनिक डेस्कटॉप सर्च इंटरफ़ेस को समझना बहुत आसान होगा। हालाँकि, यह कुछ हद तक भ्रमित करने वाला है कि डिजाइनरों ने स्पष्ट रूप से इस तथ्य को ध्यान में रखते हुए प्रोग्राम इंटरफ़ेस बनाया है कि प्रोग्राम मानक विंडोज एक्सपी थीम में काम करेगा। उसी का उपयोग करते समय क्लासिक थीम, कार्यक्रम अब उतना सुंदर नहीं दिखता। लेकिन यह स्वाद का मामला है.
पहले लॉन्च पर, प्रोग्राम आपको खोज के लिए इंडेक्स बनाने के लिए संकेत देता है। यह कुछ हद तक असामान्य लग रहा था कि इंडेक्सिंग के लिए फ़ोल्डरों का चयन करने के बाद, प्रोग्राम ने "स्टार्ट इंडेक्सिंग" जैसे किसी भी बटन को दबाने की पेशकश नहीं की, और इंडेक्सिंग स्वचालित रूप से शुरू नहीं हुई, तभी यह देखा गया कि कॉपरनिक कंप्यूटर के दौरान इंडेक्सिंग शुरू करने की कोशिश कर रहा था। निष्क्रिय था. आपको सब कुछ ठीक से कॉन्फ़िगर करने के लिए प्रोग्राम के विकल्पों में थोड़ा गहराई से जाना होगा। यह ध्यान दिया जाना चाहिए कि यहां काफी व्यापक अनुकूलन विकल्प हैं। स्वचालित निर्माणइंडेक्स: बिल्ट-इन शेड्यूलर, कंप्यूटर के निष्क्रिय होने पर इंडेक्स करने की क्षमता पृष्ठभूमि, कम प्राथमिकता के साथ। अनुक्रमण बहुत तेज़ नहीं था - 10 घंटे 51 मिनट - यह अन्य खोज इंजनों की तुलना में धीमा है (आइल ऑफ ब्लडहाउंड को छोड़कर, लेकिन कोपरनिक अभी भी iSleuthHound Technologies के विकास की तुलना में बहुत तेज़ है।
अब सूचकांक की संरचना के बारे में। सामान्य तौर पर, इसमें कुछ खास नहीं है। सामान्य और विस्तृत दोनों रूपों में फ़ाइल प्रकारों का चयन करना संभव है। यानी, शुरुआत में आप चुन सकते हैं कि आप क्या इंडेक्स करना चाहते हैं - दस्तावेज़, छवियाँ, वीडियो, संगीत। विकल्प विंडो के दूसरे टैब पर, आप एक्सटेंशन द्वारा विशिष्ट फ़ाइल प्रकारों का चयन करने में सक्षम होंगे। इसके अतिरिक्त, आप इंडेक्स को कॉन्फ़िगर कर सकते हैं ताकि, उदाहरण के लिए, 16x16 आकार से छोटे चित्र अनुक्रमित न हों या 10 सेकंड से कम लंबाई वाली ध्वनि फ़ाइलें अनुक्रमित न हों। फ़ोल्डरों से फ़ाइलों को अनुक्रमित करने के अलावा, कॉपरनिक ईमेल और संपर्कों के साथ भी काम कर सकता है पता पुस्तिका माइक्रोसॉफ्ट दृष्टिकोणऔर माइक्रोसॉफ्ट आउटलुक एक्सप्रेस, इंटरनेट एक्सप्लोरर से पसंदीदा और इतिहास का अनुक्रमण संभव है।
जहां तक खोज क्षमताओं का सवाल है, वे यहां बहुत कमजोर हैं। परीक्षणों के दौरान, यह भी पता चला कि प्रोग्राम रूसी में txt और html प्रारूपों में दस्तावेज़ों की खोज नहीं करता है, जिससे आप उन्हें केवल शीर्षकों से ढूंढ सकते हैं, सामग्री द्वारा नहीं। खोज दक्षता में सुधार करने के लिए प्रोग्राम जो एकमात्र चीज़ प्रदान करता है, वह है तार्किक संचालन के एक मानक सेट का उपयोग, और फिर भी, इस सुविधा को प्रयोगात्मक रूप से खोजा गया था, क्योंकि इसे प्रलेखित नहीं किया गया था। वैसे, प्रोग्राम की मदद से भी सब कुछ ठीक नहीं है - यह केवल इंटरनेट के माध्यम से उपलब्ध है, जो, आप देखते हैं, बहुत असुविधाजनक है, और यहां तक कि इंटरनेट पर भी संदर्भ सूचनाबहुत अधिक नहीं। जाहिर है, डेवलपर्स ने फैसला किया कि प्रोग्राम का सरल इंटरफ़ेस सामान्य सहायता की उपस्थिति का संकेत नहीं देता है। खोज क्षमताओं के बारे में बातचीत जारी रखते हुए, यह ध्यान दिया जाना चाहिए कि, प्रश्नों के कमजोर विश्लेषण के बावजूद, प्रोग्राम एक दिलचस्प खोज प्रणाली प्रदान करता है - उपयोगकर्ता फ़ाइलों के प्रकार (चित्र, वीडियो, संगीत, आदि) का चयन कर सकता है, एक खोज दर्ज कर सकता है क्वेरी करें और चयनित फ़ाइल प्रकार के लिए विशिष्ट विशेषताओं का चयन करें। उदाहरण के लिए, ध्वनि फ़ाइलों के लिए, ये एमपी3 टैग (कलाकार, एल्बम, दिनांक, आदि) से मान हो सकते हैं, उदाहरण के लिए, छवियों के लिए, आप उनका आकार (रिज़ॉल्यूशन द्वारा) चुन सकते हैं, सामान्य तौर पर, प्रत्येक प्रकार का अपना होता है अपनी सेटिंग्स. किसी विशिष्ट फ़ाइल प्रकार की खोज करने के बाद, प्रोग्राम परिणाम विंडो में एक बहुत ही जानकारीपूर्ण सूची प्रदर्शित करेगा, और यदि आपके अनुरोध में अन्य प्रकार की फ़ाइलें शामिल हैं, तो आप उन्हें एक विशिष्ट लिंक पर क्लिक करके खोल सकते हैं।
अलग से, यह परिणाम प्रदर्शन विंडो का उल्लेख करने योग्य है। मिली फ़ाइलों की सूची के नीचे, इन फ़ाइलों की सामग्री प्रदर्शित की जाती है (एक समान योजना अक्सर उपयोग की जाती है मेल क्लाइंट). सच है, पाठ देखना केवल मूल प्रारूप में ही किया जा सकता है, और कोई सादा पाठ प्रदर्शन मोड नहीं है, जो हमेशा सुविधाजनक नहीं होता है, क्योंकि इस मामले में दस्तावेज़ खोलने में अधिक समय लगता है। लेकिन, यह देखते हुए कि कॉपरनिक छवियों और संगीत की खोज कर सकता है, इन मल्टीमीडिया फ़ाइलों को देखना संभव है।
इस कार्यक्रम के संचालन के बुनियादी सिद्धांतों का वर्णन किया गया है, अब आइए देखें कि नेटवर्क के साथ काम करने के लिए कॉपरनिक डेस्कटॉप सर्च हमें क्या पेशकश कर सकता है... सिद्धांत रूप में, आप बहुत लंबे समय तक देख सकते हैं, लेकिन आप शायद ही कुछ देख पाएंगे . दूसरे शब्दों में, इस कार्यक्रम का उद्देश्य नेटवर्क-आधारित होना नहीं था। कॉपरनिक डेस्कटॉप सर्च विशेष रूप से एक होम सर्च इंजन है।
जाहिर है, इस प्रोग्राम का एकमात्र (सबसे तार्किक) अनुप्रयोग एक घरेलू कंप्यूटर है। यहां यह एक या दो शब्दों से युक्त सभी सरल उपयोगकर्ता खोज प्रश्नों का पूरी तरह से सामना करेगा, ढूंढें आवश्यक जानकारी, और फ़ाइल प्रकार के आधार पर खोज का विभाजन और कम प्राथमिकता मोड में पृष्ठभूमि अनुक्रमण के साथ मल्टीमीडिया फ़ाइलों के लिए समर्थन, एक सुखद इंटरफ़ेस के साथ मिलकर, केवल प्रोग्राम को अनुभवहीन उपयोगकर्ताओं के बीच विश्वास हासिल करने की ताकत देता है।
आधिकारिक साइट
वितरण आकार: 2.6 एमबीआईएसवाईएस डेस्कटॉप 
विस्तार करने के लिए तस्वीर पर क्लिक करें
बहुत सशक्त कार्यक्रम. सभी प्रकार के कार्यों के साथ उपकरणों के स्तर के संदर्भ में, यह सूची में अगले SearchInform खोज सिस्टम के कहीं करीब है। एक ही समय में आकार स्थापना फ़ाइल 40 एमबी से अधिक! यह कहना कठिन है कि ऐसे आयामों में क्या निचोड़ा जा सकता है, क्योंकि वही SearchInform, समान कार्यक्षमता के साथ, 15Mb लेता है।
यहां इंस्टालेशन प्रक्रिया भी बहुत सुखद नहीं है, या कहें तो इंस्टालेशन प्रक्रिया भी नहीं। प्रोग्राम डाउनलोड करने से पहले भी आपसे रजिस्ट्रेशन करने के लिए कहा जाएगा, अन्यथा कोई रास्ता नहीं है। अगला, इंटरफ़ेस. यह बहुत अच्छी तरह से बनाया गया है, कुछ भी अनावश्यक चीज़ नज़र में नहीं आती है, हालाँकि, ये उस व्यक्ति के प्रभाव हैं जो पहले से ही कुछ हद तक इसका आदी है। किसी नौसिखिया के लिए यह पता लगाना आसान नहीं होगा कि कहां और क्या स्थित है, कहां क्लिक करना है और अंततः कहां खोजना है। काम शुरू करने से पहले सहायता पढ़ने की अत्यधिक अनुशंसा की जाती है - आप बहुत सारी परेशानी और समय बचाएंगे। बाकी सब चीज़ों के साथ कार्यक्रम में रूसी भाषा के लिए समर्थन का पूर्ण अभाव भी जुड़ गया है। अच्छा नहीं है। इसके अलावा, यहां की खिड़कियां नियंत्रणों से अधिक भरी नहीं हैं, लेकिन उन्हें इसके लिए मल्टी-मॉड्यूल और उपयोग के साथ भुगतान करना पड़ता है अतिरिक्त खिड़कियाँ. उदाहरण के लिए, खोज क्वेरीज़ एक प्रोग्राम लॉन्च करके दर्ज की जाती हैं, और इंडेक्स प्रबंधन दूसरे प्रोग्राम का उपयोग करके किया जाता है। खोज क्वेरी भी यहां अलग-अलग पॉप-अप विंडो में दर्ज की जाती हैं। यह कहना मुश्किल है कि कौन सा बेहतर है - एक अतिभारित इंटरफ़ेस या सर्वव्यापी मल्टी-विंडोज़, बल्कि यह स्वाद का मामला है;
जब इंडेक्स बनाने की बात आती है, तो प्रोग्राम नए इंडेक्स के लिए विकल्प सेट करने की प्रक्रिया को सरल बनाने के लिए सुविधाएँ प्रदान करता है। इन सुविधाओं में कई शामिल हैं तैयार टेम्पलेटफ़ोल्डर "मेरे दस्तावेज़", "मेल", "मेल और दस्तावेज़", "विशिष्ट फ़ोल्डर", "फ़ाइल प्रकारों के चयन के साथ फ़ोल्डर", आदि के लिए इंडेक्स बनाने के लिए। ऐसे टेम्पलेट पहले चरण में इंडेक्स के निर्माण को सरल बनाते हैं। इंडेक्स के साथ काम करने की उपयोगिता में बहुत अच्छा इंटरफ़ेस नहीं है, जो कुछ जटिलता के साथ डराता है (ईमानदारी से कहें तो यह एक बहुत ही व्यक्तिपरक मूल्यांकन है), हालांकि, यदि आप इसे देखें, तो यह कई उपयोगी विकल्प प्रदान करता है और, सामान्य तौर पर , इसके उपयोग से ज्यादा परेशानी नहीं होती है। ISYS डेस्कटॉप विभिन्न डेटा स्रोतों से डेटा को अनुक्रमित कर सकता है, और ऐसी अनुक्रमणिका के लिए कई लचीली सेटिंग्स भी प्रदान करता है। के बीच अतिरिक्त सुविधाओंअनुक्रमण के लिए: SQL, FTP, TRIM Context, WORLDOX 2002, स्क्रिप्ट के लिए समर्थन। इंडेक्स बनाते समय, यदि आपने "फ़ाइल प्रकारों के चयन के साथ फ़ोल्डर" आइटम का चयन किया है, तो आपके पास मैन्युअल रूप से (एक्सटेंशन द्वारा) इंडेक्सिंग के लिए फ़ाइल प्रकारों का चयन करने का अवसर है। यह कहा जाना चाहिए कि समर्थित फ़ाइल प्रकारों की एक बड़ी संख्या है, लेकिन आप मौजूदा सूची में अपना स्वयं का प्रकार (एक्सटेंशन) नहीं जोड़ पाएंगे। आप एक अनुक्रमण अनुसूचक की उपस्थिति भी नोट कर सकते हैं। एक इंडेक्स बनाने और 20 गीगाबाइट जानकारी को संसाधित करने में ISYS डेस्कटॉप को 6 घंटे और 13 मिनट लगे, अंततः एक अच्छा समय और बनाई गई फ़ाइल का आकार - 7.9 जीबी दिखा।
इस प्रोग्राम की खोज क्षमताएं काफी अच्छी हैं। ISYS में जो उपयोग किया जाता है वह तार्किक संचालन के लिए पारंपरिक समर्थन से कहीं अधिक शक्तिशाली है। उन्नत खोज क्षमताओं के बीच, प्रोग्राम समानार्थक शब्द और एक सॉर्टिंग फ़िल्टर (पथ, नाम और फ़ाइल निर्माण की तारीख के अनुसार) का उपयोग प्रदान करता है। तार्किक ऑपरेटरों का सेट मानक सेट की तुलना में कुछ हद तक व्यापक है। तार्किक संचालन के अलावा, प्रोग्राम आपको कई अन्य ऑपरेटरों के साथ काम करने की अनुमति देता है, जो सिद्धांत रूप में, कुछ प्रकार की खोज को प्रतिस्थापित कर सकता है, उदाहरण के लिए, विशेष ऑपरेटरों का उपयोग करके पार्सिंग के साथ खोज को पूरी तरह से प्रतिस्थापित किया जा सकता है। मुझे बहुत आश्चर्य हुआ कि कार्यक्रम में आकृति विज्ञान का उपयोग करके कोई खोज नहीं है। यह एक गंभीर चूक है, क्योंकि रूपात्मक विश्लेषण का उपयोग करते समय खोज दक्षता में काफी सुधार होता है। इसके अलावा, महत्वपूर्ण शब्दों की कोई सूची नहीं है, लेकिन महत्वहीन शब्दों की एक विस्तृत सूची है। "अनुमानित खोज" और "अनुमानित विश्लेषण" जैसे खोज कार्यों की भी घोषणा की गई है।
ISYS कई प्रकार की खोज क्वेरी का विकल्प प्रदान करता है, अर्थात् दृश्य प्रकार। यह खोज क्वेरी दर्ज करने के लिए विभिन्न प्रकार की विंडो का उपयोग करके किया जाता है, हालांकि, वास्तव में, कोई भी विंडो ऊपर सूचीबद्ध तकनीकों के अलावा अन्य तकनीकों के उपयोग की अनुमति नहीं देती है।
खोज परिणाम बहुत जानकारीपूर्ण हैं और प्रासंगिकता के आधार पर क्रमबद्ध दस्तावेज़ों की सूची के रूप में प्रदर्शित होते हैं। चयनित दस्तावेज़ का पूर्वावलोकन नीचे प्रदर्शित किया गया है। कॉपरनिक डेस्कटॉप सर्च के विपरीत, यहां पूर्वावलोकन केवल सादे पाठ के रूप में उपलब्ध है; दस्तावेज़ों को उनके मूल प्रारूप में प्रदर्शित करना संभव नहीं था, चाहे वह वर्ड, एचटीएमएल या पीडीएफ हो, हालांकि, सिद्धांत रूप में, यह बहुत महत्वपूर्ण नहीं है। प्रोग्राम आपको पाए गए दस्तावेज़ों को कुछ मानदंडों के अनुसार समूहों में विभाजित करने की अनुमति देता है (डिफ़ॉल्ट रूप से वे प्रासंगिकता के अनुसार विभाजित होते हैं)। आप अलग-अलग फ़ोल्डरों का चयन करके पहले से पाए गए दस्तावेज़ों को भी देख सकते हैं (यह तब सुविधाजनक होता है जब परिणाम बहुत बड़ी संख्या में दस्तावेज़ उत्पन्न करता है)।
कॉर्पोरेट नेटवर्क पर प्रोग्राम का उपयोग करना भी बहुत उचित है, क्योंकि यह नेटवर्क खोज को व्यवस्थित करने के लिए अच्छे अवसर प्रदान करता है। खोज प्रणाली एक सार्वजनिक सूचकांक के निर्माण पर आधारित है जिसमें सार्वजनिक रूप से उपलब्ध ऑनलाइन संसाधनों से अनुक्रमित डेटा शामिल होता है।
वास्तव में, ISYS का कार्यक्रम ध्यान देने योग्य है, कम से कम इससे परिचित होना। यह कार्यक्रम बड़ी संख्या में कार्यों के साथ एक परिपक्व परियोजना है (बेशक, हमेशा नहीं और हर किसी को उनकी आवश्यकता नहीं होती है, लेकिन फिर भी)। संभावनाएं अज्ञात हैं कि प्रोग्राम में खोज क्वेरी के प्रसंस्करण के संदर्भ में कुछ सुधार देखने को मिलेंगे, लेकिन इस पलइसे लगभग सार्वभौमिक उपयोग के लिए अनुशंसित किया जा सकता है। और यह देखते हुए कि यह अभी भी घरेलू सिस्टम के लिए बहुत भारी है, इसकी स्थापना के लिए मुख्य स्थान कॉर्पोरेट नेटवर्क हैं।
आधिकारिक साइट:
वितरण का आकार: 40 एमबीसर्चइनफॉर्म 
विस्तार करने के लिए तस्वीर पर क्लिक करें
संभवतः SearchInform इंटरफ़ेस के विवरण के साथ तुरंत शुरुआत करना उचित नहीं है। हमें पहले इंस्टॉलेशन प्रक्रिया का वर्णन करना चाहिए, या इसके विवरणों में से एक का: आप इंटरनेट कनेक्शन के बिना प्रोग्राम इंस्टॉल नहीं कर सकते। तथ्य यह है कि पहले लॉन्च से पहले, प्रोग्राम को उपयोगकर्ता पंजीकरण (निःशुल्क) की आवश्यकता होती है और सभी दर्ज किए गए डेटा को सर्वर पर भेजता है। जाहिर है, पायरेसी के खिलाफ लड़ाई में डेवलपर्स को ऐसे उपाय करने पड़े, लेकिन इससे इंस्टॉलेशन में आसानी पर सकारात्मक प्रभाव नहीं पड़ा।
प्रोग्राम इंटरफ़ेस सभी आम तौर पर स्वीकृत नियमों के अनुपालन में डिज़ाइन किया गया है, हालांकि, पहली नज़र में, यह कुछ हद तक बोझिल है। पहली बार प्रोग्राम का उपयोग करने पर ऐसा लगता है कि यह बहुत जटिल है, कभी-कभी यह याद रखना आसान नहीं होता है कि वांछित विकल्प किस मेनू या किस टैब पर स्थित है, हालांकि, लंबे समय तक उपयोग के साथ, इंटरफ़ेस अब इतना जटिल नहीं लगता है . मुख्य बात यह है कि पहले प्रमाणपत्र पढ़ें।
इंटरफ़ेस को थोड़ा समझने के बाद, आप एक इंडेक्स बनाना शुरू कर सकते हैं। यह प्रक्रिया अपने आप में बहुत सरल है और अनुक्रमण गति, यहाँ तक कि आँख से भी, समीक्षा में अन्य सभी खोज इंजनों की तुलना में काफी अधिक है। स्पष्ट परीक्षण संख्याएँ दर्शाती हैं कि अनुक्रमण गति के मामले में SearchInform dtSearch और iSYS से दोगुना तेज़ है! कार्यक्रम ने 3 घंटे 17 मिनट के रिकॉर्ड समय में 20 गीगाबाइट की मात्रा में प्रदान किए गए डेटा को अनुक्रमित किया। और बनाए गए इंडेक्स का आकार सबसे छोटा 4.4 जीबी निकला - Google डेस्कटॉप सर्च से 100 मेगाबाइट कम।
प्रोग्राम नियमित फ़ाइलों और फ़ोल्डरों के अलावा, ईमेल को अनुक्रमित करने, डेटाबेस (!) और अन्य बाहरी स्रोतों (डीएमएस, सीआरएम) को जोड़ने और अनुक्रमित करने का भी समर्थन करता है, अनुक्रमण के दौरान तुरंत आप एक रूपात्मक खोज करने के लिए एक शब्दकोश और सभी विशेषताओं को निर्दिष्ट कर सकते हैं। फ़ाइलें अनुक्रमित की जा सकती हैं. सूचकांक बनाने के बाद, दस्तावेज़ों के लिए पहली परीक्षण खोज करने का प्रयास करते समय, आप कुछ हद तक भ्रमित हो सकते हैं: "यहां दो प्रकार की खोज हैं, लेकिन मुझे किसकी आवश्यकता है?" जैसा कि पहले उल्लेख किया गया है, मुख्य बात प्रमाणपत्र को पढ़ना है, फिर सब कुछ स्पष्ट हो जाएगा। प्रोग्राम वास्तव में दो प्रकार की खोज कर सकता है - वाक्यांश खोज और क्वेरी पाठ की सामग्री के समान दस्तावेज़ों की खोज।
खोज क्वेरी का विश्लेषण करने के लिए सभी मुख्य कार्यों का विवरण ऊपर दिया गया था, इसलिए अब हम केवल इस कार्यक्रम द्वारा प्रदान की गई खोज क्षमताओं को सूचीबद्ध करेंगे। आइए वाक्यांश खोज से शुरू करें: बेशक, रूपात्मक खोज, उद्धरण खोज, तार्किक संचालन, शब्द विश्लेषण के साथ खोज (शब्द की शुरुआत में, अंत में, मध्य भाग में, या पूर्ण मिलान पर खोजें), मिश्रित उद्धरण खोज ( जब क्वेरी के सभी शब्द दस्तावेज़ में मौजूद होने चाहिए, लेकिन जरूरी नहीं कि दर्ज क्रम में हों), त्रुटि सुधार के साथ खोजें, समानार्थक शब्द का उपयोग करें, "लगभग उद्धरण खोज" (प्रविष्ट वाक्यांश को उद्धरण के रूप में खोजें, लेकिन अन्य शब्द हो सकते हैं) प्रविष्ट शब्दों के बीच उपस्थित रहें), आदि। सूचीबद्ध कुछ विकल्पों की अपनी विशिष्ट सेटिंग्स हैं। इसके अलावा, महत्वहीन शब्दों के शब्दकोश का उपयोग करना संभव है, और कार्यक्रम में पहले से ही इन शब्दों की एक तैयार सूची है; आप खोज के लिए प्राथमिकता वाले शब्दों के शब्दकोश का भी उपयोग कर सकते हैं (बेशक, आपको इसे भरना होगा)। अपने आप को)।
यहां, सिद्धांत रूप में, हमने वाक्यांश खोज की सभी मुख्य विशेषताओं की संक्षेप में समीक्षा की।
आइए इस कार्यक्रम की विशेषताओं पर विचार करें - समान दस्तावेज़ों की खोज करें। डेवलपर्स का दावा है कि यह किसी भी तरह से एक साधारण पाठ खोज नहीं है, यह बिल्कुल "समान लोगों की खोज" है - यह बिल्कुल इसी तरह से वर्णित है, लेकिन ओह ठीक है, आप इसे जो चाहें कह सकते हैं - मुख्य बिंदु यह है . इंटरनेट पर एक त्वरित खोज से पता चल सकता है कि तथाकथित "समान खोज" पाठ विश्लेषण के क्षेत्र में एक नया विकास है। यह प्रणाली आपको ऐसे पाठ ढूंढने की अनुमति देती है जो शब्दार्थ सामग्री में समान हैं। सबसे सुखद बात यह थी कि परीक्षण खोज क्वेरी आयोजित करने के बाद, यह पता चला कि सिद्धांत अभ्यास के साथ काफी मेल खाता है! प्रोग्राम वास्तव में समान सामग्री वाले दस्तावेज़ों की खोज करता है और उन्हें समानता के प्रतिशत के आधार पर क्रमबद्ध करते हुए एक सूची में प्रदर्शित करता है।
इसके बाद, आइए देखें कि कॉर्पोरेट नेटवर्क पर काम करने के लिए SearchInform (विशेष रूप से, इसका कॉर्पोरेट संस्करण SearchInform कॉर्पोरेट) क्या ऑफ़र करता है। एप्लिकेशन दो प्रकार के होते हैं: सर्वर साइड और यूजर साइड। सर्वर भाग स्वतंत्र रूप से निर्दिष्ट इंडेक्स को संसाधित करता है, और उपयोगकर्ता उन्हें सौंपे गए एक्सेस अधिकारों के आधार पर, खोज के लिए उनका उपयोग कर सकते हैं। उपयोगकर्ताओं को स्वचालित रूप से उपयोग करके कॉन्फ़िगर किया जा सकता है हिसाब किताबविंडोज़ (पेशेवर शब्दों में, SearchInform NTFS विंडोज़ प्रमाणीकरण का उपयोग करता है), और मैन्युअल रूप से (उपयोगकर्ताओं को अलग से जोड़ना होगा)। प्रत्येक उपयोगकर्ता को कुछ अनुक्रमितों तक पहुंच की अनुमति दी जा सकती है या अस्वीकार किया जा सकता है, और उपयोगकर्ताओं को समूहों में भी जोड़ा जा सकता है। सामान्य तौर पर, नेटवर्क पर काम करने के लिए SearchInform की सेटिंग्स लचीलेपन के मामले में Google और सुविधा और सरलता के मामले में Ishhound सर्वर से आगे हैं।
आधिकारिक साइट:
वितरण आकार: 14.7 एमबी अनुक्रमण गति की तुलना
| खोज प्रणाली | अनुक्रमण समय | सूचकांक आकार |
| ब्लडहाउंड प्रोफेसर डिलक्स 4.5 | 38 घंटे 46 मिनट | 19 जीबी |
| आइसिस डेस्कटॉप 7.0 | 6 घंटे 13 मिनट | 7.9 जीबी |
| डीटीसर्च 7.0 | 6 घंटे 3 मिनट | 8.6 जीबी |
| Google डेस्कटॉप खोज एंटरप्राइज़ | 8 घंटे 17 मिनट | 4.5 जीबी |
| कॉपरनिक डेस्कटॉप खोज * | 10 घंटे 51 मिनट | 7 जीबी |
| सर्चइनफॉर्म 1.5.02 | 3 घंटे 17 मिनट | 4.4 जीबी |
* रूसी पाठ वाले अधिकांश दस्तावेज़.एचटीएमएल और .txt, हालांकि उन्हें अनुक्रमित किया गया था, उनके नाम के अलावा उन्हें ढूंढना असंभव था
सभी कार्यक्रम ध्यान देने योग्य हैं.
परीक्षणों और समीक्षा में प्रस्तुत प्रत्येक कार्यक्रम की सावधानीपूर्वक जांच के आधार पर, कुछ निष्कर्ष निकाले जा सकते हैं। इसलिए, Google डेस्कटॉप सर्च कॉपरनिक डेस्कटॉप सर्च घरेलू सूचना खोज प्रणाली के रूप में अनुभवहीन उपयोगकर्ता के लिए काफी उपयुक्त है। वे साथ अच्छा काम करते हैं सरल प्रश्न, उपयोगकर्ता पर सेटिंग्स का बोझ नहीं डालेंगे और इसके अलावा, पूरी तरह से मुफ़्त हैं। कॉर्पोरेट खोज इंजन बाज़ार में प्रवेश करने का Google का प्रयास अभी तक बहुत उचित नहीं है: इसे ठीक से काम करने के लिए, प्रोग्राम को अतिरिक्त मॉड्यूल से लैस करने की आवश्यकता है, और इसे स्थापित करना बहुत आसान नहीं है। इसलिए, स्व-व्याख्यात्मक नाम डेस्कटॉप सर्च, कॉपरनिक और गूगल अपने पीछे "डेस्कटॉप" सर्च इंजनों का स्थान आरक्षित रखते हैं।
सच है, अधिक शक्तिशाली समाधान - dtSearch, iSYS और SearchInform भी फुलप्रूफ नहीं हैं और उपयोगकर्ताओं को उनके "डेस्कटॉप" संस्करण प्रदान करते हैं। लेकिन Google और कॉपरनिक के मुफ़्त सॉफ़्टवेयर के विपरीत, उचित मूल्य पर। बेशक, आपको शक्ति, गति और कार्यक्षमता के लिए भुगतान करना होगा। लेकिन dtSearch, iSYS और SearchInform के डेवलपर्स का मुख्य ध्यान, निश्चित रूप से, कॉर्पोरेट क्षेत्र पर है। नेटवर्किंग, कार्यक्षमता, अनुक्रमण और खोज गति ही इन उत्पादों को उनके "प्रतिस्पर्धियों" से अलग करती है। परीक्षण परिणामों के आधार पर, पसंदीदा की पहचान की गई - SearchInform। प्रोग्राम समान दस्तावेज़ों को खोजने की क्षमता प्रदान करता है, इसमें सबसे तेज़ अनुक्रमण और खोज गति है, और इसमें कार्यों का एक अच्छा सेट है।
यह क्या है
DuckDuckGo एक काफी प्रसिद्ध ओपन सोर्स सर्च इंजन है। सर्वर संयुक्त राज्य अमेरिका में स्थित हैं. अपने स्वयं के रोबोट के अलावा, खोज इंजन अन्य स्रोतों से परिणामों का उपयोग करता है: याहू, बिंग, विकिपीडिया।
बेहतर
DuckDuckGo खुद को एक ऐसे सर्च इंजन के रूप में स्थापित करता है जो अधिकतम गोपनीयता और गोपनीयता प्रदान करता है। सिस्टम उपयोगकर्ता के बारे में कोई डेटा एकत्र नहीं करता है, लॉग संग्रहीत नहीं करता है (कोई खोज इतिहास नहीं), उपयोग करें कुकीज़जितना संभव हो उतना सीमित।
DuckDuckGo उपयोगकर्ताओं से व्यक्तिगत जानकारी एकत्र या साझा नहीं करता है। यह हमारी गोपनीयता नीति है।
गैब्रियल वेनबर्ग, डकडकगो के संस्थापक
आप इसकी आवश्यकता क्यों है
सभी बड़े खोज इंजनवे मॉनिटर के सामने मौजूद व्यक्ति के बारे में डेटा के आधार पर खोज परिणामों को वैयक्तिकृत करने का प्रयास करते हैं। इस घटना को "फ़िल्टर बबल" कहा जाता है: उपयोगकर्ता केवल वही परिणाम देखता है जो उसकी प्राथमिकताओं के अनुरूप होते हैं या जिन्हें सिस्टम ऐसा मानता है।
एक वस्तुनिष्ठ चित्र बनाता है जो इंटरनेट पर आपके पिछले व्यवहार पर निर्भर नहीं करता है, और आपके प्रश्नों के आधार पर Google और Yandex विषयगत विज्ञापन को समाप्त कर देता है। DuckDuckGo के साथ जानकारी खोजना आसान है विदेशी भाषाएँ, जबकि Google और Yandex डिफ़ॉल्ट रूप से रूसी-भाषा साइटों को प्राथमिकता देते हैं, भले ही अनुरोध किसी अन्य भाषा में दर्ज किया गया हो।

यह क्या है
नॉट एविल एक ऐसी प्रणाली है जो अज्ञात टोर नेटवर्क की खोज करती है। इसका उपयोग करने के लिए, आपको इस नेटवर्क पर जाना होगा, उदाहरण के लिए एक विशेष लॉन्च करके।
नॉट एविल अपनी तरह का एकमात्र खोज इंजन नहीं है। इसमें LOOK (टोर ब्राउज़र में डिफ़ॉल्ट खोज, जिसे नियमित इंटरनेट से एक्सेस किया जा सकता है) या TORCH (टोर नेटवर्क पर सबसे पुराने खोज इंजनों में से एक) और अन्य हैं। Google के स्पष्ट संकेत के कारण हमने ईविल पर निर्णय नहीं लिया (केवल आरंभ पृष्ठ को देखें)।
बेहतर
यह वहां खोजता है जहां Google, Yandex और अन्य खोज इंजन आमतौर पर बंद होते हैं।
आप इसकी आवश्यकता क्यों है
टोर नेटवर्क में कई संसाधन शामिल हैं जो कानून का पालन करने वाले इंटरनेट पर नहीं मिल सकते हैं। और जैसे-जैसे इंटरनेट की सामग्री पर सरकारी नियंत्रण कड़ा होता जाएगा, उनकी संख्या बढ़ती जाएगी। Tor इंटरनेट के भीतर एक प्रकार का नेटवर्क है जिसके अपने सोशल नेटवर्क, टोरेंट ट्रैकर्स, मीडिया, ट्रेडिंग प्लेटफार्म, ब्लॉग, लाइब्रेरी इत्यादि।
3. यासी

यह क्या है
YaCy एक विकेन्द्रीकृत खोज इंजन है जो P2P नेटवर्क के सिद्धांत पर काम करता है। प्रत्येक कंप्यूटर जिस पर मुख्य सॉफ़्टवेयर मॉड्यूल स्थापित है, स्वतंत्र रूप से इंटरनेट को स्कैन करता है, अर्थात यह एक खोज रोबोट के अनुरूप है। प्राप्त परिणाम एक सामान्य डेटाबेस में एकत्र किए जाते हैं जिसका उपयोग सभी YaCy प्रतिभागियों द्वारा किया जाता है।
बेहतर
यह कहना मुश्किल है कि यह बेहतर है या बदतर, क्योंकि YaCy खोज को व्यवस्थित करने का एक पूरी तरह से अलग दृष्टिकोण है। एकल सर्वर और मालिक कंपनी की अनुपस्थिति परिणामों को किसी की प्राथमिकताओं से पूरी तरह स्वतंत्र बनाती है। प्रत्येक नोड की स्वायत्तता सेंसरशिप को समाप्त कर देती है। YaCy डीप वेब और गैर-अनुक्रमित सार्वजनिक नेटवर्क को खोजने में सक्षम है।
आप इसकी आवश्यकता क्यों है
यदि आप ओपन सोर्स सॉफ़्टवेयर और मुफ़्त इंटरनेट के समर्थक हैं, सरकारी एजेंसियों और बड़े निगमों के प्रभाव के अधीन नहीं हैं, तो YaCy आपकी पसंद है। इसका उपयोग किसी कॉर्पोरेट या अन्य स्वायत्त नेटवर्क के भीतर खोज को व्यवस्थित करने के लिए भी किया जा सकता है। और भले ही YaCy रोजमर्रा की जिंदगी में बहुत उपयोगी नहीं है, लेकिन खोज प्रक्रिया के मामले में यह Google का एक योग्य विकल्प है।
4. पीपल

यह क्या है
Pipl एक सिस्टम है जिसे किसी विशिष्ट व्यक्ति के बारे में जानकारी खोजने के लिए डिज़ाइन किया गया है।
बेहतर
पिपल के लेखकों का दावा है कि उनके विशेष एल्गोरिदम "नियमित" खोज इंजनों की तुलना में अधिक कुशलता से खोज करते हैं। विशेष रूप से, सोशल नेटवर्क प्रोफाइल, टिप्पणियों, सदस्य सूचियों और विभिन्न डेटाबेस को प्राथमिकता दी जाती है जो लोगों के बारे में जानकारी प्रकाशित करते हैं, जैसे अदालती फैसलों के डेटाबेस। इस क्षेत्र में पिपल के नेतृत्व की पुष्टि Lifehacker.com, TechCrunch और अन्य प्रकाशनों के आकलन से होती है।
आप इसकी आवश्यकता क्यों है
अगर आपको अमेरिका में रहने वाले किसी व्यक्ति के बारे में जानकारी ढूंढनी है तो Pipl Google से कहीं अधिक प्रभावी होगा। रूसी अदालतों के डेटाबेस स्पष्ट रूप से खोज इंजन के लिए दुर्गम हैं। इसलिए, वह रूसी नागरिकों के साथ इतना अच्छा व्यवहार नहीं करता है।

यह क्या है
फाइंडसाउंड्स एक अन्य विशेष खोज इंजन है। खुले स्रोतों में विभिन्न ध्वनियाँ खोजता है: घर, प्रकृति, कारें, लोग, इत्यादि। सेवा रूसी में प्रश्नों का समर्थन नहीं करती है, लेकिन रूसी भाषा टैग की एक प्रभावशाली सूची है जिसका उपयोग आप खोज के लिए कर सकते हैं।
बेहतर
आउटपुट में केवल ध्वनियाँ हैं और कुछ भी अतिरिक्त नहीं है। सेटिंग्स में आप वांछित प्रारूप और ध्वनि गुणवत्ता सेट कर सकते हैं। पाई गई सभी ध्वनियाँ डाउनलोड के लिए उपलब्ध हैं। पैटर्न द्वारा एक खोज है.
आप इसकी आवश्यकता क्यों है
यदि आपको बंदूक की गोली की आवाज, दुधमुंहे कठफोड़वे के वार या होमर सिम्पसन के रोने की आवाज तुरंत पता लगाने की जरूरत है, तो यह सेवा आपके लिए है। और हमने इसे केवल उपलब्ध रूसी-भाषा प्रश्नों में से चुना है। अंग्रेजी में इसका फलक और भी व्यापक है।
सचमुच, किसी विशेष सेवा के लिए विशेष दर्शकों की आवश्यकता होती है। लेकिन अगर ये आपके भी काम आ जाए तो क्या होगा?

यह क्या है
वोल्फ्राम|अल्फा एक कम्प्यूटेशनल खोज इंजन है। युक्त लेखों के लिंक के बजाय कीवर्ड, यह उपयोगकर्ता के अनुरोध का तैयार उत्तर प्रदान करता है। उदाहरण के लिए, यदि आप अंग्रेजी में खोज फ़ॉर्म में "न्यूयॉर्क और सैन फ्रांसिस्को की आबादी की तुलना करें" दर्ज करते हैं, तो वोल्फ्राम|अल्फा तुरंत तुलना के साथ तालिकाएं और ग्राफ़ प्रदर्शित करेगा।
बेहतर
तथ्य खोजने और डेटा की गणना करने के लिए यह सेवा दूसरों से बेहतर है। वोल्फ्राम|अल्फा विज्ञान, संस्कृति और मनोरंजन सहित विभिन्न क्षेत्रों से वेब पर उपलब्ध ज्ञान एकत्र और व्यवस्थित करता है। यदि इस डेटाबेस में किसी खोज क्वेरी का तैयार उत्तर है, तो सिस्टम इसे प्रदर्शित करता है, यदि नहीं, तो यह गणना करता है और परिणाम प्रदर्शित करता है। इस मामले में, उपयोगकर्ता को केवल कुछ भी अनावश्यक नहीं दिखता है।
आप इसकी आवश्यकता क्यों है
उदाहरण के लिए, यदि आप एक छात्र, विश्लेषक, पत्रकार या शोधकर्ता हैं, तो आप अपने काम से संबंधित डेटा खोजने और गणना करने के लिए वोल्फ्राम|अल्फा का उपयोग कर सकते हैं। सेवा सभी अनुरोधों को नहीं समझती है, लेकिन यह लगातार विकसित हो रही है और स्मार्ट होती जा रही है।

यह क्या है
डॉगपाइल मेटासर्च इंजन Google, Yahoo और अन्य लोकप्रिय प्रणालियों के खोज परिणामों की एक संयुक्त सूची प्रदर्शित करता है।
बेहतर
सबसे पहले, डॉगपाइल कम विज्ञापन प्रदर्शित करता है। दूसरे, सेवा विभिन्न खोज इंजनों से सर्वोत्तम परिणाम खोजने और दिखाने के लिए एक विशेष एल्गोरिदम का उपयोग करती है। डॉगपाइल डेवलपर्स के अनुसार, उनके सिस्टम संपूर्ण इंटरनेट पर सबसे पूर्ण खोज परिणाम उत्पन्न करते हैं।
आप इसकी आवश्यकता क्यों है
यदि आपको Google या किसी अन्य मानक खोज इंजन पर जानकारी नहीं मिलती है, तो डॉगपाइल का उपयोग करके एक साथ कई खोज इंजनों में इसे खोजें।

यह क्या है
बोर्डरीडर मंचों, प्रश्न एवं उत्तर सेवाओं और अन्य समुदायों में पाठ खोज के लिए एक प्रणाली है।
बेहतर
सेवा आपको अपने खोज क्षेत्र को सामाजिक प्लेटफ़ॉर्म तक सीमित करने की अनुमति देती है। विशेष फ़िल्टर के लिए धन्यवाद, आप तुरंत ऐसे पोस्ट और टिप्पणियाँ पा सकते हैं जो आपके मानदंडों से मेल खाते हैं: भाषा, प्रकाशन तिथि और साइट का नाम।
आप इसकी आवश्यकता क्यों है
बोर्डरीडर पीआर विशेषज्ञों और अन्य मीडिया विशेषज्ञों के लिए उपयोगी हो सकता है जो कुछ मुद्दों पर जनता की राय में रुचि रखते हैं।
अंत में
वैकल्पिक खोज इंजनों का जीवन अक्सर क्षणभंगुर होता है। लाइफ़हैकर ने यांडेक्स की यूक्रेनी शाखा के पूर्व महानिदेशक सर्गेई पेट्रेंको से ऐसी परियोजनाओं की दीर्घकालिक संभावनाओं के बारे में पूछा।

सर्गेई पेट्रेंको
Yandex.Ukraine के पूर्व जनरल डायरेक्टर।
वैकल्पिक खोज इंजनों के भाग्य के लिए, यह सरल है: छोटे दर्शकों के साथ बहुत विशिष्ट परियोजनाएं होना, इसलिए स्पष्ट व्यावसायिक संभावनाओं के बिना या, इसके विपरीत, उनकी अनुपस्थिति की पूरी स्पष्टता के साथ।
यदि आप लेख में उदाहरणों को देखते हैं, तो आप देख सकते हैं कि ऐसे खोज इंजन या तो एक संकीर्ण लेकिन लोकप्रिय जगह में विशेषज्ञ हैं, जो शायद, अभी तक Google या Yandex के रडार पर ध्यान देने योग्य नहीं हुआ है, या वे परीक्षण कर रहे हैं रैंकिंग में एक मूल परिकल्पना, जो अभी तक नियमित खोज में लागू नहीं है।
उदाहरण के लिए, यदि टोर पर कोई खोज अचानक मांग में आ जाती है, यानी, Google के दर्शकों के कम से कम एक प्रतिशत को वहां के परिणामों की आवश्यकता होती है, तो, निश्चित रूप से, सामान्य खोज इंजन इस समस्या को हल करना शुरू कर देंगे कि कैसे उन्हें ढूंढें और उपयोगकर्ता को दिखाएं। यदि दर्शकों के व्यवहार से पता चलता है कि बड़ी संख्या में प्रश्नों में उपयोगकर्ताओं के एक महत्वपूर्ण अनुपात के लिए, उपयोगकर्ता के आधार पर कारकों को ध्यान में रखे बिना दिए गए परिणाम अधिक प्रासंगिक लगते हैं, तो यांडेक्स या Google ऐसे परिणाम देना शुरू कर देंगे।
इस लेख के संदर्भ में "बेहतर बनें" का अर्थ "हर चीज़ में बेहतर होना" नहीं है। हां, कई पहलुओं में हमारे नायक यांडेक्स (यहां तक कि बिंग से भी दूर) से बहुत दूर हैं। लेकिन इनमें से प्रत्येक सेवा उपयोगकर्ता को कुछ ऐसा देती है जो खोज उद्योग के दिग्गज नहीं दे सकते। निश्चित रूप से आप भी ऐसी ही परियोजनाओं को जानते हैं। हमारे साथ साझा करें - आइए चर्चा करें।
इंटरनेट पर व्यावसायिक जानकारी खोजें
इंटरनेट खोज इंटरनेट पर काम करने का एक महत्वपूर्ण तत्व है। वेब संसाधनों की सटीक संख्या आधुनिक इंटरनेटशायद ही कोई निश्चित रूप से जानता हो। वैसे भी गिनती अरबों में है. किसी निश्चित समय पर आवश्यक जानकारी का उपयोग करने में सक्षम होने के लिए, चाहे काम या मनोरंजन के उद्देश्य से, आपको सबसे पहले इसे संसाधनों के इस लगातार भरे हुए महासागर में ढूंढना होगा।
किसी इंटरनेट खोज के सफल होने के लिए, दो शर्तों को पूरा किया जाना चाहिए: प्रश्नों को अच्छी तरह से तैयार किया जाना चाहिए और उन्हें उचित स्थानों पर पूछा जाना चाहिए। दूसरे शब्दों में, उपयोगकर्ता को एक ओर, अपनी खोज रुचियों को खोज क्वेरी की भाषा में अनुवाद करने में सक्षम होना आवश्यक है, और दूसरी ओर, खोज इंजन, उपलब्ध खोज उपकरण, उनके फायदे और का अच्छा ज्ञान होना चाहिए। नुकसान, जो उसे प्रत्येक विशिष्ट मामले में सबसे उपयुक्त खोज उपकरण चुनने की अनुमति देगा।
वर्तमान में, ऐसा कोई एक संसाधन नहीं है जो सभी इंटरनेट खोज आवश्यकताओं को पूरा करता हो। इसलिए, यदि आप अपनी खोज को गंभीरता से लेते हैं, तो आपको अनिवार्य रूप से विभिन्न उपकरणों का उपयोग करना होगा, प्रत्येक का सबसे उपयुक्त मामले में उपयोग करना होगा।
बुनियादी इंटरनेट खोज उपकरणनिम्नलिखित मुख्य समूहों में विभाजित किया जा सकता है:
खोज इंजन;
वेब निर्देशिकाएँ;
सहायता संसाधन;
इंटरनेट पर खोज के लिए स्थानीय कार्यक्रम.
सबसे लोकप्रिय खोज उपकरण हैंखोज इंजन– तथाकथित इंटरनेट सर्च इंजन (खोज इंजन)। वैश्विक स्तर पर शीर्ष तीन नेता काफी स्थिर हैं - Google, Yahoo! और बिंग. कई देशों में, स्थानीय सामग्री के साथ काम करने के लिए अनुकूलित उनके अपने स्थानीय खोज इंजन इस सूची में जोड़े जाते हैं। उनकी मदद से, आप सैद्धांतिक रूप से कई लाखों साइटों के पन्नों पर कोई विशिष्ट शब्द पा सकते हैं। उपयोगकर्ता के दृष्टिकोण से, खोज इंजन का मुख्य नुकसान अपरिहार्य उपस्थिति हैसूचना शोरपरिणामों में. यह उन परिणामों के लिए पारंपरिक नाम है जो किसी न किसी कारण से खोज सूची में शामिल होते हैं और अनुरोध के अनुरूप नहीं होते हैं।
कई अंतरों के बावजूद, सभी इंटरनेट खोज इंजन समान सिद्धांतों पर काम करते हैं और तकनीकी दृष्टिकोण से, समान उपप्रणालियों से बने होते हैं। सर्च इंजन का पहला संरचनात्मक भाग है विशेष कार्यक्रम, के लिए इस्तेमाल होता है स्वचालित खोजऔर बाद में वेब पेजों का अनुक्रमण। ऐसे कार्यक्रमों को आमतौर पर स्पाइडर या बॉट कहा जाता है। वे वेब पेजों के कोड को देखते हैं, उन पर स्थित लिंक ढूंढते हैं और इस तरह नए वेब पेज खोजते हैं। वे भी हैं वैकल्पिक तरीकासूचकांक में साइट का समावेश. कई खोज इंजन संसाधन स्वामियों को स्वतंत्र रूप से अपने डेटाबेस में एक साइट जोड़ने का अवसर प्रदान करते हैं। हालाँकि, वेब पेजों को फिर डाउनलोड, विश्लेषण और अनुक्रमित किया जाता है। वे संरचनात्मक तत्वों को उजागर करते हैं, कीवर्ड ढूंढते हैं, और अन्य साइटों और वेब पेजों के साथ उनके कनेक्शन निर्धारित करते हैं। अन्य ऑपरेशन भी किए जाते हैं, जिसके परिणामस्वरूप एक खोज इंजन इंडेक्स डेटाबेस का निर्माण होता है। यह डेटाबेस किसी भी सर्च इंजन का दूसरा मुख्य तत्व है। वर्तमान में, कोई भी पूर्णतः पूर्ण सूचकांक डेटाबेस नहीं है जिसमें सभी इंटरनेट सामग्री के बारे में जानकारी हो। क्योंकि विभिन्न खोज इंजनउपयोग विभिन्न कार्यक्रमवेब पेजों की खोज करना और विभिन्न एल्गोरिदम का उपयोग करके उनके सूचकांक का निर्माण करना, खोज इंजन सूचकांक डेटाबेस में काफी भिन्नता हो सकती है। कुछ साइटों को कई खोज इंजनों द्वारा अनुक्रमित किया जाता है, लेकिन संसाधनों का एक निश्चित प्रतिशत हमेशा केवल एक खोज इंजन के डेटाबेस में शामिल होता है। प्रत्येक खोज इंजन में सूचकांक के ऐसे मूल और गैर-अतिव्यापी भाग की उपस्थिति हमें एक महत्वपूर्ण व्यावहारिक निष्कर्ष निकालने की अनुमति देती है: यदि आप केवल एक खोज इंजन का उपयोग करते हैं, यहां तक कि सबसे बड़ा भी, तो आप निश्चित रूप से उपयोगी लिंक का एक निश्चित प्रतिशत खो देंगे .
इंटरनेट सर्च इंजन का अगला भाग वास्तविक खोज और सॉर्टिंग प्रोग्राम है। ये प्रोग्राम दो मुख्य कार्यों को हल करते हैं: सबसे पहले, वे डेटाबेस में पेज और फ़ाइलें ढूंढते हैं जो आने वाले अनुरोध से मेल खाते हैं, और फिर परिणामी डेटा सरणी को विभिन्न मानदंडों के अनुसार क्रमबद्ध करते हैं। खोज लक्ष्यों को प्राप्त करने में सफलता काफी हद तक उनके कार्य की प्रभावशीलता पर निर्भर करती है।
इंटरनेट सर्च इंजन का अंतिम तत्व यूजर इंटरफ़ेस है। किसी भी वेबसाइट के लिए सौंदर्यशास्त्र और सुविधा की सामान्य आवश्यकताओं के अलावा, खोज इंजन इंटरफेस की एक और महत्वपूर्ण आवश्यकता होती है: उन्हें प्रश्नों को लिखने और स्पष्ट करने के साथ-साथ परिणामों को सॉर्ट करने और फ़िल्टर करने के लिए विभिन्न उपकरण प्रदान करने चाहिए। खोज इंजनों के लाभ स्रोतों का उत्कृष्ट कवरेज, डेटाबेस सामग्री का अपेक्षाकृत तेज़ अद्यतनीकरण और हैं एक अच्छा विकल्पअतिरिक्त प्रकार्य।
खोज इंजन के साथ काम करने का मुख्य उपकरण एक क्वेरी है।
इंटरनेट खोजों के लिए, विशेष एप्लिकेशन का भी उपयोग किया जाता है जो स्थानीय कंप्यूटर पर इंस्टॉल किए जाते हैं। ऐसा हो सकता है सरल कार्यक्रम, और डेटा खोज और विश्लेषण के काफी जटिल परिसर। सबसे आम हैं ब्राउज़रों के लिए खोज प्लगइन्स, एक विशिष्ट खोज सेवा के साथ काम करने के लिए डिज़ाइन किए गए ब्राउज़र पैनल, और परिणामों का विश्लेषण करने की क्षमताओं वाले मेटासर्च पैकेज।
वेब निर्देशिकाएँ – ये वे संसाधन हैं जिनमें साइटों को विषयगत श्रेणियों में विभाजित किया गया है। यदि उपयोगकर्ता केवल प्रश्नों के माध्यम से खोज इंजन के साथ काम करता है, तो कैटलॉग में विषयगत अनुभागों को उनकी संपूर्णता में देखना संभव है। निर्देशिकाओं और स्वचालित खोज इंजनों के बीच दूसरा मूलभूत अंतर यह है कि, एक नियम के रूप में, लोग सीधे उन्हें भरने, संसाधनों को देखने और साइट को एक श्रेणी या किसी अन्य में वर्गीकृत करने में शामिल होते हैं। वेब निर्देशिकाओं को आमतौर पर सार्वभौमिक और विषयगत में विभाजित किया जाता है। सार्वभौमिक लोग यथासंभव अधिक से अधिक विषयों को कवर करने का प्रयास करते हैं। आप उनमें कुछ भी पा सकते हैं: कविता से संबंधित वेबसाइटों से लेकर कंप्यूटर संसाधन. दूसरे शब्दों में, उनकी खोज का दायरा अधिकतम है. विषयगत निर्देशिकाएँ एक विशिष्ट विषय में विशेषज्ञ होती हैं, जो संसाधन कवरेज की चौड़ाई को कम करके अधिकतम खोज गहराई प्रदान करती हैं।
कैटलॉग के फायदे तुलनात्मक रूप से हैं उच्च गुणवत्तासंसाधन, क्योंकि इसमें प्रत्येक साइट को एक व्यक्ति द्वारा देखा और चुना जाता है। साइटों का विषयगत समूहन आपको समान विषयों की साइटों को आसानी से व्यवस्थित करने की अनुमति देता है। संचालन का यह तरीका उन साइटों की खोज करने के लिए अच्छा है जो आपकी रुचि के विषय पर नई हैं - यह खोज इंजन का उपयोग करने से अधिक सटीक है। किसी भी विषय क्षेत्र से पहली बार परिचित होने के साथ-साथ अस्पष्ट प्रश्नों की खोज के लिए वेब कैटलॉग का उपयोग करने की अनुशंसा की जाती है - आपके पास कैटलॉग के अनुभागों के माध्यम से "भटकने" का अवसर होगा और अधिक सटीक रूप से यह निर्धारित करने का अवसर होगा कि आपको वास्तव में क्या चाहिए।
वेब निर्देशिकाओं के नुकसान ज्ञात हैं। सबसे पहले, यह डेटाबेस की धीमी पुनःपूर्ति है, क्योंकि कैटलॉग में किसी साइट को शामिल करने के लिए मानवीय भागीदारी की आवश्यकता होती है। दक्षता के मामले में, एक वेब निर्देशिका खोज इंजन की प्रतिद्वंद्वी नहीं है। इसके अलावा, डेटाबेस आकार के मामले में वेब निर्देशिकाएं खोज इंजन से काफी कमतर हैं।
इंटरनेट खोज के बारे में बात करते समय, हम ऐसे कई शब्दों को नज़रअंदाज़ नहीं कर सकते जो इस क्षेत्र से निकटता से संबंधित हैं और अक्सर खोज इंजनों का वर्णन और मूल्यांकन करने के लिए उपयोग किए जाते हैं। उदाहरण के लिए:चौड़ाई और गहराई इंटरनेट खोज। व्यापक खोज वह है जो जानकारी के यथासंभव अधिक से अधिक स्रोतों को पकड़ती है। इस मामले में, कम से कम अनुरोध के लिए उपयुक्त एक या किसी अन्य साइट का उल्लेख पर्याप्त माना जाता है। खोज गहराई से तात्पर्य प्रत्येक विशिष्ट संसाधन के अनुक्रमण और उसके बाद की खोज के विवरण से है। उदाहरण के लिए, कई खोज इंजन अलग-अलग साइटों को अलग-अलग तरीके से अनुक्रमित करने का तरीका अपनाते हैं। बड़ी और लोकप्रिय साइटों को अधिकतम सीमा तक अनुक्रमित किया जाता है; रोबोट ऐसे संसाधन का एक भी पृष्ठ न चूकने का प्रयास करते हैं। उसी समय, अन्य साइटों पर, केवल शीर्षक पृष्ठ और कुछ सामग्री पृष्ठों को अनुक्रमित किया जा सकता है। ये परिस्थितियाँ स्वाभाविक रूप से बाद की खोजों को प्रभावित करती हैं। गहन खोज इस सिद्धांत पर काम करती है "खोज विषय से संबंधित किसी भी डेटा को चूकने की तुलना में परिणामों में अनावश्यक जानकारी शामिल करना बेहतर है।"
अक्सर आपके सामने ऐसी अवधारणाएँ आ सकती हैंवैश्विक और स्थानीय इंटरनेट खोज। स्थानीय इंटरनेट खोजें उपयोगकर्ता की भौगोलिक स्थिति को ध्यान में रखती हैं और उन परिणामों को प्राथमिकता देती हैं जो किसी तरह किसी विशिष्ट देश या इलाके से संबंधित होते हैं। वैश्विक खोज के दौरान, इस जानकारी को ध्यान में नहीं रखा जाता है, और खोज सभी उपलब्ध संसाधनों में की जाती है।
इंटरनेट खोज इंजन पर अनुरोध करते समय, निम्नलिखित लागू होता है: विभिन्न तरीकेखोजना। अधिकांश इंटरनेट मशीनों पर पाए जाने वाले विशिष्ट खोज मोड में शामिल हैं:सरल और उन्नत खोजना। एक साधारण खोज आपको एक अनुरोध में केवल एक खोज सुविधा निर्दिष्ट करने की अनुमति देती है। उन्नत खोज कई स्थितियों से एक क्वेरी बनाना संभव बनाती है, उन्हें तार्किक ऑपरेटरों के साथ जोड़ती है।
खोज क्वेरी को परिष्कृत करने के लिए, विभिन्नफिल्टर . फ़िल्टर किसी क्वेरी को लिखने के लिए वे या अन्य सहायक साधन हैं जो क्वेरी शर्तों के सामग्री पक्ष से संबंधित नहीं हैं, लेकिन कुछ औपचारिक सुविधा द्वारा खोज परिणामों को सीमित करते हैं। इसलिए, उदाहरण के लिए, खोज करते समय फ़ाइल प्रकार फ़िल्टर का उपयोग करते समय, उपयोगकर्ता सिस्टम को उसके अनुरोध के विषय से संबंधित जानकारी प्रदान नहीं करता है, बल्कि प्राप्त परिणामों को उसके अनुरोध की स्थिति में निर्दिष्ट एक निश्चित फ़ाइल प्रकार तक सीमित कर देता है।
अधिकांश उपयोगकर्ताओं के लिए, सार्वभौमिक खोज इंजन इंटरनेट खोज का मुख्य और अक्सर एकमात्र साधन हैं। वे स्रोतों की अच्छी कवरेज के साथ-साथ बुनियादी खोज समस्याओं को हल करने के लिए पर्याप्त उपकरणों का एक सेट भी प्रदान करते हैं।
सार्वभौमिक खोज इंजनों का बाज़ार काफी बड़ा है। हमने सबसे प्रसिद्ध खोज इंजनों का विश्लेषण करने का प्रयास किया, और परिणाम तालिका 1 में प्रस्तुत किए।
एक सार्वभौमिक खोज इंजन चुनते समय, इसकी सहायता से प्राप्त संसाधनों की गुणवत्ता एक महत्वपूर्ण भूमिका निभाती है। आप "मार्कर विधि" का उपयोग करके विशिष्ट कार्यों के लिए पसंदीदा खोज इंजन निर्धारित कर सकते हैं। इसका सार यह है कि पहले एक निश्चित विषयगत खोज क्वेरी संकलित की जाती है, जिसके बाद लोगों के एक समूह - इस क्षेत्र के विशेषज्ञ - को चुने गए विषय पर सर्वोत्तम, उनकी राय में, इंटरनेट संसाधनों की पहचान करने के लिए सर्वेक्षण किया जाता है। सर्वेक्षण डेटा के आधार पर, मार्कर साइटों की एक सूची तैयार की जाती है जो अनुरोध के लिए प्रासंगिक होने की गारंटी देती है और जिसमें उच्च गुणवत्ता वाली जानकारी होती है। फिर अनुरोध परीक्षण किए गए खोज इंजनों को भेजा जाता है। मूल्यांकन का तर्क सरल है: खोज परिणामों में मार्कर साइटें जितनी अधिक स्थित होंगी, परीक्षण विषय पर जानकारी खोजने के लिए एक विशेष संसाधन उतना ही बेहतर उपयुक्त होगा।
एक समय में दर्जनों सेवाओं में उपनाम की जाँच करना, फेसबुक पर रीपोस्ट की गिनती करना और ट्विटर अकाउंट कनेक्शन की कल्पना करना।
स्टार्टअप्स के बीच सोशल मीडिया सामग्री विश्लेषण एक गर्म विषय है। खोज पोस्ट और लोगों के लिए अधिक से अधिक सेवाएँ हर साल सामने आती हैं। लेकिन उनमें से कई या तो जल्दी ही गायब हो जाते हैं, अधूरी अवस्था में उपलब्ध होते हैं, या उपयोग में महंगे होते हैं।
इस सामग्री में उनमें से कुछ शामिल हैं जो आपको वास्तव में उपयोगी या बस दिलचस्प जानकारी जल्दी और स्वतंत्र रूप से प्राप्त करने की अनुमति देते हैं।
1. प्रोफ़ाइल खोजें
खोज प्रणाली नाकआपको दुनिया के अग्रणी विश्वविद्यालयों की वेबसाइटों और अमेरिकी आपराधिक डेटाबेस सहित चार दर्जन सेवाओं में किसी व्यक्ति की प्रोफ़ाइल खोजने की अनुमति देता है:

दुर्भाग्य से, कुछ साइटें जिनके लिए आप बॉक्स चेक कर सकते हैं, अब काम नहीं करतीं। उदाहरण के लिए, Google अंकल सैम, 5 साल पहले बंद हो गया। लेकिन इसके बावजूद और अन्य स्निच जाम - उपयोगी सेवा, जो आपको किसी व्यक्ति के बारे में जानकारी खोजते समय महत्वपूर्ण रूप से समय बचाने की अनुमति देता है।
यदि किसी सेवा के लिए खोज परिणामों वाले ब्लॉक के बजाय एक खाली स्क्रीन प्रदर्शित होती है, तो उन्हें देखने के लिए आपको लिंक का अनुसरण करना होगा एक नई विंडो खोलें:
2. हैशटैग खोजें
इसे इस्तेमाल करना बहुत आसान है. आपको वांछित हैशटैग को खोज फ़ॉर्म में दर्ज करना होगा और एक सेकंड में छह सामाजिक नेटवर्क में इसके साथ टैग किए गए हालिया पोस्ट की एक सूची दिखाई देगी:
3. हालिया ट्वीट्स का विश्लेषण
सेवा आपको खोज शब्द, हैशटैग या खाता नाम वाले अंतिम सौ ट्वीट्स की एक सूची प्राप्त करने की अनुमति देती है। और ये ट्वीट करने वाले लोगों और इन्हें बनाने के समय के बारे में कुछ विश्लेषणात्मक जानकारी भी प्राप्त करें:

मान लीजिए कि आप यह पहचानना चाहते हैं कि किस उपयोगकर्ता के कारण ट्विटर के किसी लेख पर असामान्य रूप से अधिक संख्या में क्लिक हुए। हम नवीनतम 100 ट्वीट्स देखते हैं और देखते हैं कि मूल अवधारणा का उल्लेख करने वाले लोगों में से किसके सबसे अधिक अनुयायी हैं:

मालिकों सशुल्क सदस्यताविश्लेषण के लिए बड़ी संख्या में ट्वीट उपलब्ध हैं:

4. ट्विटर अकाउंट विश्लेषण
पर मेंशन ऐपआप खाते का नाम दर्ज कर सकते हैं और कनेक्शन आरेख के रूप में इसके बारे में जानकारी प्राप्त कर सकते हैं (कौन सबसे अधिक बार रीट्वीट करता है, कौन से हैशटैग का उपयोग करता है, आदि):

5. मानचित्र पर ट्वीट खोजें
यदि आप मानचित्र पर किसी भी स्थान पर क्लिक करते हैं, तो आप आस-पास किए गए नवीनतम ट्वीट्स पढ़ सकते हैं:

6. सामाजिक नेटवर्क पर उल्लेखों की संख्या
साझा गिनतीसामाजिक नेटवर्क पर किसी लेख/साइट की लोकप्रियता का मूल्यांकन करने में मदद करता है। आप यूआरएल दर्ज करते हैं और कुछ सेकंड के बाद फेसबुक, Google+, पिनटेरेस्ट, लिंक्डइन और स्टंबल अपॉन पर उल्लेखों के आंकड़े आते हैं:

7. फ़ोरम खोजें
बोर्डरीडरमंचों और संदेश बोर्डों के लिए एक खोज इंजन है:

आपदा के पैमाने के आकलन से पता चला कि इस पोर्टल पर रूस के प्रति निवासी लगभग 4 प्रतिक्रियाएँ हैं।
8. हम सामाजिक नेटवर्क के माध्यम से लॉगिन तोड़ते हैं
हम Knowem.com पर जाते हैं और व्यक्ति का उपनाम दर्ज करते हैं। जवाब में, हमें यह जानकारी प्राप्त होती है कि यह किन सेवाओं पर पंजीकृत है:

9. ईमेल द्वारा किसी व्यक्ति का नाम निर्धारित करें
यदि आप अभी भी Google में लोगों के ईमेल पते टाइप करके उन्हें ढूंढ रहे हैं, तो आपको यह तरीका छोड़ देना चाहिए। आख़िरकार, pipl.com है। आप अपना ईमेल (उपनाम) दर्ज करें और सामाजिक नेटवर्क पर प्रोफाइल की एक सूची प्राप्त करें:
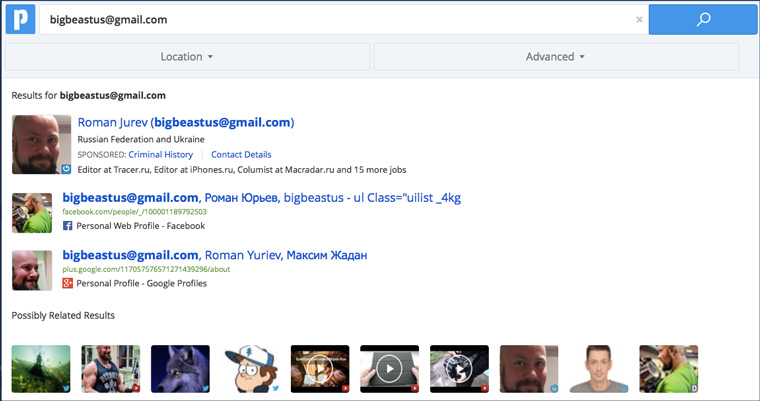
जानकारी हमेशा सटीक या पूर्ण नहीं होती, लेकिन सेवा अत्यंत उपयोगी होती है।
बस इतना ही। यह सोशलमेंशन (समीक्षाओं का अधूरा विश्लेषण), योमैपिक (मानचित्र पर वीके और इंस्टाग्राम से फ़ोटो की खोज) और यांडेक्स के बारे में बात करने लायक था।



