(less often - part of a compound sentence, or a paragraph). If the translation unit of the source text exactly matches the translation unit stored in the database (exact match, eng. exact match), it can be automatically substituted into the translation. The new segment may also differ slightly from the one stored in the database (fuzzy matching, eng. fuzzy match). Such a segment can also be substituted into the translation, but the translator will have to make the necessary changes.
In addition to speeding up the process of translating repetitive fragments and changes made to already translated texts (for example, new versions of software products or changes in legislation), PP systems also ensure the uniformity of the translation of terminology in the same fragments, which is especially important for technical translation. On the other hand, if a translator regularly substitutes exact matches retrieved from translation memory into his translation without controlling their use in a new context, the quality of the translated text may deteriorate.
In each specific software system, data is stored in its own own format(text format in Wordfast, base Access data in Deja Vu), but there is an international standard TMX (Eng. Translation Memory eXchange format ) which is based on XML and which can be generated by almost all software systems. Thanks to this, the translations made can be used in different applications, that is, a translator working with OmegaT can use a PR created in TRADOS and vice versa.
Most software systems at least support the creation and use of user dictionaries, the creation of new databases based on parallel texts (eng. alignment), as well as semi-automatic extraction of terminology from original and parallel texts.
Popular PP software systems
According to surveys of the use of PP systems, the most popular systems include:
The English Wikipedia has a list comparing the capabilities of different systems.
Translation memory standards and formats
- TMX (Translation Memory Exchange Format) format. This standard allows interchange between different translation memory providers. TMX is a commonly used format among translators and is best suited for importing and exporting translation memories. The latest version of this format - 1.4b allows you to restore original documents and their translation from a TMX file.
- TBX (Termbase Exchange format - Termbase Exchange). This LISA (Localization Industry Association) format is currently being revised and republished according to ISO 30042. This standard allows the exchange of terminology, including detailed lexical information. The core base of TBX is defined by the standards: ISO 12620, ISO 12200 and ISO 16642. ISO 12620 provides a registry of well-defined "data categories" with standardized names that function as data element types or predefined values. ISO 12200 (also known as MARTIF) provides the framework for the TBX framework. ISO 16642 (also known as the Terminological Markup Framework) includes a structural metamodel for Terminological Markup Languages in general.
- SRX is designed to improve the TMX format and make transferring translation memories more efficient between programs. The ability to specify the segmentation rules that were used in the previous translation improves the efficiency of identifying segments in the current text with the content of the PG.
- GMX GILT stands for Globalization, Internationalization, Localization, and Translation (Globalization, internationalization, localization, translation). The GILT Metrics standard consists of three parts: GMX-V for volume metrics, GMX-C for complexity metrics, GMX-Q for quality metrics. The proposed GILT Metrics standard aims to quantify the scope of work and quality requirements for the implementation of GILT objectives.
- OLIF is an XML-compatible open standard that is used for the exchange of terminological and lexical data. Although it was originally used as a way to exchange lexical data between private machine translation lexicons, this format has gradually evolved into a more general terminological exchange standard.
- XLIFF (XML Localization Interchange File Format - XML Localization Interchange File Format), created as a single file format for interchange, which is recognized by all software tools localization. XLIFF is the best way to exchange information in XML format in today's translation industry.
- TransWS (Translation Web Services - translation web services), defines the required parameters for calling web services when sending and receiving files and messages related to localization projects. It was conceived as a deployed system for automating the localization process using services on the Internet.
- xml:tm, this approach to translation memory is based on the concept of text memory, which allows the combination of author's memory and translation memory. The xml:tm format was provided to Lisa OSCAR by XML-INTL.
Advantages and disadvantages
Advantages
- Reducing the time and volume of the translator's work
- Improving translation consistency, especially when a group of translators are working on the same project.
- Increasing profits by increasing the productivity of a translator, a group of translators
- Improving the quality of services by increasing the accuracy and uniformity of the translation of terms, especially in specialized texts.
Flaws
- Can make the translation more "dry"; the very essence of the text is lost if the translation using the translation memory is performed by an unskilled translator
- Often there is no connection between the sentence / text proposed by the program with neighboring sentences and with the text as a whole
- The original must be in electronic form
- One unnoticed mistake can spread to the entire project
- It is necessary to train the program itself, and when changing jobs - perhaps more than once (if employers work with different TM programs)
- Suitable for all types of texts
- High cost of licensed software
see also
Literature
- Grabovsky VN Technology Translation Memory // Bridges. Journal of Translators. 2004. No. 2. - S. 57-62.
Links
- Don't do the same translation twice // Computerra Online, February 14, 2005.
Notes
Wikimedia Foundation. 2010 .
See what "Translation Memory" is in other dictionaries:
Contents 1 In psychology 2 In computer technology... Wikipedia
Mosaic with the image ... Wikipedia
A text in one language along with its translation into another language. "Parallel text alignment" is the identification of matching sentences in both halves of the parallel text. Large collections of parallel texts are called ... ... Wikipedia
Parallel text (bitext) text in one language together with its translation into another language. "Parallel text alignment" is the identification of matching sentences in both halves of the parallel text. Large gatherings ... ... Wikipedia
Translation memory (TM, sometimes referred to as "Translation Memory") is a database containing a set of previously translated texts. One entry in such a database corresponds to a segment or "translation unit" (English ... ... Wikipedia
The article talks about a new translator tool - Translation Memory (TM) technology, thanks to which the translation activity is mechanized.
Neural networks in the work of a translator
Machine translation theories, developed in a sluggish manner from time immemorial, have received a major boost since the 1970s. This was due to significant advances in the field of modeling intellectual activity. In addition to purely scientific interest, this was due to the growing role of interlingual communications in the modern world.
In addition to electronic dictionaries and phrasebooks, by the mid-1990s, "electronic translators" (they began to be called MT technology) became quite widespread. In principle, "electronic translators" are programs that could process an entire text. True, the output was not quite what was needed, and frankly, it was not at all. In order for the result of the MT technology to become a truly coherent text, a person had to work hard on it.
The concept of “machine translation” has become well known. Domestic Stylus programs have become quite widespread among us (now it is called prompt And Socrates). However, interest in such programs after a period of initial curiosity has gradually declined, and now it is not great, even though they have been largely finalized. Currently, they are used mainly for exploring the content of foreign-language sites on the Internet, as well as for reading and writing. emails in a foreign language.
By and large, the work of a translator has not fundamentally changed over the centuries. Yes, computers appeared, sort of fast and convenient typewriters. Yes, there are "electronic translators". However, despite the fact that MT technologies have improved, they have not become a tool that has a wide scope and allows you to truly save time and effort.
What is Translation Memory Technology
Technology has become a new tool for the translator Translation_Memory(TM). In the West, TM technology and the translator toolkit created on its basis - Translation Memory Tools (TMT) - are well known and widely used. A feature of this technology is the mechanization of translation activities, and not its automation in the form in which the creators of the MT technology saw it. Moreover, this more modest, at first glance, decision brought immeasurably more practical benefits than the global plan of "electronic translators".
The difference from electronic dictionaries and other translator tools is that a typical TM class program is based on neural networks that are able to simulate the work to a certain extent. human brain when processing data. These networks are capable of learning and analyzing complex datasets that are difficult to process using linear algorithms.
These programs use a fuzzy algorithm that allows you to look up words not only in their dictionary forms, but also in other forms, for example, in a different case. In addition, they can find phrases in a different word order. A self-organizing artificial neural network is able to find patterns and determine the relationships between them. The program compares the fragment that you are currently working on with the contents of the database, and provides this information to the display. It can determine that a given fragment is similar to a similar fragment in the system's memory, for example, 99%, 74%, or even 20%.
Every translator knows the feeling that the phrase he is currently struggling with has already been met somewhere, once, at least in an approximate form. Moreover, it came across either in the same material, or in some other, translated earlier. Just some kind of deja vu ... I would like to see it, this phrase, at least for reference, in order to sensibly formulate the one you are working on now ...
You start leafing through the original back, rummaging through the bookshelf. And it often happened that the desired phrase actually showed up. Most often, when it's too late, already after the work on the translation is finished. It seems that at such a moment I would give everything for a tool that would help to find the necessary text. Even now, when you type the text of the translation using a computer, and not on a typewriter, it is always a pity to redo what was composed with such difficulty. The translator's long-standing dream is to come up with some means that would relieve the need to translate the same phrase several times.
This kind of idea underlies the creation of the Translation Memory technology, or simply TM, on the basis of which more or less workable programs began to appear from the late 80s - early 90s. In fact, such a program is a control shell that works with one or another plug-in database (TM) and which I would call a moneybox of translations. TM is a computerized version of a large filing cabinet that holds every phrase you've ever translated, in pairs, in both the original language and the translated language. Each such pair is called bilingual. The program will instantly remind you how this phrase was translated last time. Access to information is easy and fast.
Overview of the main programs of the Translation Memory class
Currently, there are several software products on the world market that use TM technology. They differ from each other, and sometimes significantly. However, they all share some common functionality.
For example, they usually have a text editor that has two parallel windows. One window is intended for the original text, the second - for translation. When the original text fragment is displayed in the original window (it can be a sentence, a paragraph, a single word), the search for a similar fragment in the database begins. If there is exactly the same fragment in memory, it is displayed in the translation window automatically. If exactly the same fragment was not found, but some similar one was found, then the found fragment is displayed in the program window with an indication of the match percentage.
The translator edits the translation text proposed by the program, bringing it into line with the original, sends it to the database memory and proceeds to the next one. If nothing was found at all, then the translator translates it from scratch by typing the text into the translation box. Having finished working on this fragment, the translator sends it to the database memory and proceeds to the next one. Thus, the replenishment of TM occurs automatically, as you work. Immediately after the bilingual has got into the TM, it becomes available to the user. If the TM program is located on network drive and other users work with it, the new bilingual immediately becomes available to other translators. After the original fragment and the translation fragment are sent to the database, the next fragment is displayed in the original window.
The first program of this type, called Translation Manager, was developed by IBM. Initially, IBM used Translation Manager for its own needs - for localization (adaptation to foreign languages) own software. Then Translation Manager was offered to the market as a commercial product, and for a while it had a monopoly in this area. This program is quite easy to use, is fast and provides good opportunities for user customization. Separate windows are provided for each of the three main functions - Translation, Translation Memory and Dictionary. The Translation Memory window displays matches found in memory, if any, and the Dictionary window displays terminology from dictionaries developed by IBM. There are some inconveniences in this program, for example, a complicated procedure for searching individual words in the Translation Memory.
Another program - SDLX - was developed for its own needs by an English company SDL, engaged in software localization. Each program included in the kit is installed separately. SDL Edit is, in fact, the program itself, with the help of which the translation is carried out. It has three windows showing source text, translation and Translation Memory. Note that a document to be translated cannot be imported directly into SDL Edit. First, it must be converted using SDL Convert, which is a certain inconvenience.
Program Deja Vu is popular among translators in Europe due to its flexibility and adaptability. In addition to convenience, Déjà Vu stands out from other products with the highest quality/price ratio. Compared with the two previous programs, the product in question has a number of convenient features. Experts note that from the very beginning this program was developed in contact with its future users. It is known that the latest version of Déjà Vu was tested, in particular, by Russian translators. One of them, Andrey Gerasimov, wrote a positive review of this program in the journal MultiLingual Computing & Technology
Known in our country and popular in Europe program STAR Transit. In its ideology, it is completely different from other products of this class. You have already got a certain understanding of them, and you know that they all have a central database large capacity, a piggy bank of translations in which the necessary data is found instantly (if they are there, of course). As Bill Gates would say: "Information at your fingertips". So, all Translation Memory programs have an electronic filing cabinet, but Transit does not. It's different for him. The source data and the translation are saved in text format as files that the translator places in directories of his choice. The translator can then simply tell the program which directories and even which files it needs. Then Transit forms an associative network of links, with which work is being done. Despite some advantages, Transit is not widely used in Russia. Eventually Promt, the official distributor of Transit, switched to distributing Trados' Translator's Workbench.
But Translator’s Workbench, or simply Trados, quickly became widespread in Russia, first among translation companies, and then among individual translators. Probably, this can be explained by the fact that it makes it possible to work without leaving Word, which is psychologically more comfortable. Who is pleased to look at the text, speckled with all sorts of codes in square brackets? Translator's Workbench (Trados) compared to other programs is more convenient for an ordinary translator who is not a programming specialist, it is more understandable compared to other programs of this type. In particular, the control buttons are provided with tooltips. Being in a familiar and understandable Word, you can use all its tools (for example, autotexts).
This product has full set useful tools that are present in other programs only to one degree or another. One of these tools is Analise, which allows you to analyze the original text in advance and find out if there (and how many) there are complete and incomplete matches. It is worth mentioning this handy tool, like Placeables, which allows, for example, to automatically change the numbers in the text if everything else in the translated fragment matches the one found in the translation box (TM). Very comfortable automatic function substitutions in numbers for decimal points and/or commas, time format, abbreviations, etc. to the corresponding parameters set by the translator.
The vast majority of Russian translators using TM technology prefer Translator's Workbench (Trados).
What do Translation Memory programs have in common?
Summarizing the description of the main software products of the Translation Memory class, it should be noted that they usually have a number of common functionalities.
Mixing - Alignment
This feature allows you to create moneyboxes of transfers (TM) from existing files. From two files - one with the original text and the other with the translated text - a bilingual set is created. Opposite the sentence of the source text, its translation is built. And so on for all the files that the translator has brought into a single piggy bank. The degree of convenience of the combination function different programs different.
Maintenance
As bilinguals accumulate in the database, their number can increase so much that the contents of the database can go beyond all limits. Some inaccuracies and even errors may be found, especially if the program is used on the network by many users. There will be a need to edit or clarify something, or even simply delete it. In fairness, it must be said that the mentioned program maintenance tool does not completely solve this problem - it is still difficult to deal with the clogging of translation piggy banks in practice.
Terminological Dictionary - Terminology Program
All the programs under consideration have their own terminological dictionaries, which are, in fact, electronic dictionaries known to all. Terminological dictionaries can import files in the format of dictionaries or glossaries, they can also be replenished manually.
Text editor - Document Editor
Here, in fact, the translation process is carried out. To do this, all programs have the two windows mentioned above - for the source text and for its translation. All text editors have the ability to set the degree of similarity between what is being translated into this moment source text and text in the translation box. The higher you set the similarity percentage, such as 90% or 95%, the less likely it is to find matching text there. However, you can set a smaller percentage, then you can get a lot of material that would be useful at least for reference.
Concordance (Linking usage with context) - Concordance
This is very useful feature all programs under consideration. It often happens that a term (or a combination of terms) can have several meanings or shades of meanings. By selecting a term, you can view in the window all the bilinguals available in the piggy bank, and in a variety of contexts. This always makes it easier to choose the most accurate translation of a given term or combination.
Natalya Shakhova, director of the EnRus agency, believes that most TM products save the user from having to get acquainted with various word processors. It is enough to study the features text editor the product itself, and you will be subject to all the variety of texts, whether they are presented in QuarkXPress, FrameMaker or Adobe Illustrator. There is, of course, some catch here: in order to master the next word processor or publishing system, you will need the appropriate filter program, which - what? That's right - sold for separate money! In general, the money issue is the most serious when it comes to TMT. They are not cheap (as a rule, several hundred dollars), compatibility, of course, is not. Therefore, if you purchased (and mastered!) a product for one project, then for the next one you may need to purchase another product and spend time learning it again.
Further, Natalya Shakhova notes that the West is already discussing with might and main the consequences of the widespread distribution of such programs. One of them is that a novice translator loses the opportunity to enter the market. Just as in Russia it is already very difficult for a translator to get an order if he does not have a computer and a printer, and abroad there are problems in finding employment for translators who do not have a TM program. This phenomenon also has a positive side - by hiring the owner of a TM program, the customer receives some guarantee of his professionalism. But even beginners should be able to start!
The attitude to the Translation Memory technology in our country is different.
When in 1999 the Phonetics translation agency began working with Trados Translator’s Workbench, naturally, in the course of contacts with customers, we talked about the transition to new technology. Contrary to expectations, the reaction was wary, and sometimes just negative. It turned out that the idea of machine translation had already been compromised by the thoughtless use in the 90s of programs like Stylus and Socrat. Moreover, they were often used by translators, say, not very highly qualified, who did not bother editing what the "electronic translators" issued. However, the users of these programs can also be understood - editing these texts required a lot of time and effort.
Even now, sometimes one can meet on the part of customers from among Russian organizations a wary attitude towards any innovations in the field of translation software. At the same time, foreign firms, on the contrary, require the use of programs of the Translation Memory class. Often they have established preferences, mainly Trados Translator's Workbench, as well as Star Transit. They often have ready-made TMs (money boxes of transfers) that they offer to use.
As for translators, they are quite understandably interested in the Translation Memory technology. Translation agencies are even more understandably interested in them. They deal not so much with fiction, journalism, poetry, etc., but with operating instructions, troubleshooting guides, and software localization, i.e. with those materials where there are repeating or similar fragments of text.
In its current form, Translation Memory programs seem to have reached a ceiling. Further work on their refinement goes along the path of improving their existing functionality. This leads to the fact that the programs are becoming more and more cumbersome and complex, and this despite the fact that there are no fundamentally new ideas there. The same Translator's Workbench (Trados) in its latest version overgrown with such a set of tools that simple user it is very difficult to understand them.
The operation of this program requires the presence of a separate employee in the state of the translation agency. In addition to the user manual, the documentation provides a dedicated specialist guide (TRADOS Specialist Guide). In addition, the documentation package includes the Project Management Guide, MultiTerm User Guide, and WinAlign User Guide. Even a trained translator will need a lot of effort and time to familiarize himself with hundreds of pages of these documents.
A group of researchers at the University of Maryland, Baltimore County (USA), led by Professor S. Nirenburg, a well-known specialist in the field of artificial intelligence and machine translation, is looking for new solutions. While the developments are at the stage of theoretical studies, and most likely, bringing these studies to the stage of a commercial product will require considerable time.
Attention is drawn to the fact that mainly foreign companies work on the market of translator tools. Hopefully this won't go on forever. The potential of theoretical developments of Russian specialists in the field of semantic analysis is very large. Our research in this area has reached a very high level. There is every reason to expect that these developments will materialize in the form of fundamentally new linguistic technologies that will allow the translator to fully unleash the creative potential.
Journal of a practicing translator"Bridges", one of the few professional periodicals for translators. The journal publishes articles by translators of various specialties, both oral and written. On the pages of the journal, translators specializing in various fields of knowledge have the opportunity to discuss actual problems, argue with each other, share the secrets of professional skills.
Translation memory or Translation memory
Translation memory (TM, sometimes called "Translation memory") is a database containing a set of previously translated texts. One entry in such a database corresponds to a "translation unit" (English translation unit), which is usually taken as one sentence (less often - part of a compound sentence, or a paragraph). If the next sentence of the source text exactly matches the sentence stored in the database (exact match, English exact match), it can be automatically substituted into the translation. The new sentence may also differ slightly from the one stored in the database (fuzzy match). Such a sentence can also be substituted in the translation, but the translator will have to make the necessary changes.
In addition to speeding up the process of translating repeated fragments and changes made to already translated texts (for example, new versions of software products or changes in legislation), Translation Memory systems also ensure the uniformity of the translation of terminology in the same fragments, which is especially important for technical translation. On the other hand, if a translator regularly substitutes exact matches retrieved from translation memory into his translation without controlling their use in a new context, the quality of the translated text may deteriorate.
Each specific Translation Memory system stores data in its own format (text format in Wordfast, Access database in Deja Vu), but there is an international standard TMX (English Translation Memory eXchange format), which is based on XML and which can be generated by almost all PP systems. Thanks to this, the results of the work of translators can be exchanged between applications, that is, a translator working with OmegaT can use the translation memory created in Trados (Trados) and vice versa.
Most Translation Memory systems at least support the creation and use of user dictionaries, the creation of new databases based on parallel texts (English alignment), as well as semi-automatic extraction of terminology from original and parallel texts.
List of translation memory software systems
According to recent reviews of the use of systems translation memory are among the most popular systems.
TM is a database where completed translations are stored. The TM technology works on the principle of accumulation: during the transfer process, the original segment (offer) and its translation are stored in the TM. When processing a new text received for translation, the system compares each of its sentences with the segments stored in the database. If an identical or similar segment is found, the translation of that segment is displayed along with the translation and a percentage match. Words and phrases that differ from the stored text are highlighted. Thus, the translator needs to translate only new segments and edit overlapping ones. Each change or new translation is saved in the TM. As a result, there is no need to translate the same sentence twice.
On the other hand, when working with major projects the translator is faced with the problem of consistent application of a terminological glossary during a long project or rapid reuse of a previously translated text. By their very nature, these routine tasks relatively easy (unlike machine translation) to formalize and program.
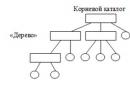
Each TM database entry is a unit (sentence or paragraph) of parallel texts (usually in two languages). Such a database stores previous translations for the purpose of their possible reuse and for solving problems of quick content search. Despite the fact that programs equipped with translation memory are called computer-aided/assisted translation (CAT) systems, they should not be confused with machine translation programs (machine translation) - translation memory does not translate anything by itself, while how machine translation is based on the generation of translations based on the results of grammatical analysis of the source text.
As a rule, a translation memory record consists of two segments: in the source (source) and target (target) languages. If an identical (or similar) segment in the source language occurs in the text, the segment in the target language will be found in the translation memory and offered to the translator as the basis for a new translation. The automatically found text can be used as is, edited or completely rejected. Most programs use the fuzzy matching algorithm, which significantly improves their functionality, since in this case it is possible to find sentences that only remotely resemble the phrases you are looking for, but, nevertheless, suitable for subsequent editing.
The benefits of using such software may not be obvious at first - however, as the database fills up, the results of automatic substitution of bases for translation will become more accurate and regular.
The architecture of an automated system and its functionality may vary. The search tools can work with entire segments or with individual words or phrases, allowing the translator to perform terminological searches. The system also includes separate program to work with a glossary containing approved terms for use in the project. Some systems work with machine translation programs. The main operating interface is either built directly into an existing word processor such as Word or is a standalone editor. The system must include filters for import-export of files of various formats. In addition, many, if not all, systems have a facility to add to the translation memory segments from the translator's usually old translated files.
What applies to language learning also applies to Translation Memories.
The "empty" system remembers terms and sentences.
A "translation memory" is being built - Translation Memory (TM).
TM becomes a "linguistic memory" for the product or for the company's activities as a whole.
TM systems: SDLX, TRADOS, Deja Vu, Star Transit, Trans Suite 2000, WordFast, WordFisher, ACROSS.
COMBINED SYSTEMS
The MP and TM technologies complement each other, but do not duplicate each other. The MP system is ready for use immediately after installation (although this does not exclude the possibility that the user will want to change something in the dictionary, translation algorithms, etc. in the process of work). The TM system needs to be specially tuned to translate texts in a particular area, and the more similar these texts are to each other (for example, such a system is used to translate standard contracts), the less time is required for tuning.
In this regard, the emergence of hybrids - example-based machine translation - programs that combine machine translation systems and TM is quite logical (for example, the PROMT company created an integrated technology PROMT Term and PROMT For TRADOS, which combines the TM TRADOS system and the machine translation system - PROMTXT Professional). PROMT For TRADOS (P4T) is designed to integrate the PROMT machine translation system and the TM TRADOS system:
Translation in the TRADOS system;
Translation in the PROMT system of segments not found in TM;
Inserting translated PROMT segments into TM.
Scheme of an automated translation chain based on the integrated PROMT-TRADOS technology
The use of integrated technology makes the process of translating large amounts of documentation manageable and increases its economic efficiency.
An example of the implementation of projects using the integrated PROMT-TRADOS technology.
Suppose you need to translate instructions for a mini-ATS.
1. At the first stage, the PROMT TerM program is used. The documents are analyzed, and the main terminology is identified, which is entered into the dictionaries of the PROMT machine translation system.
2. Machine translation (MT) is being performed with the dictionary connected, terminological work on the correction of the dictionary continues.
3. The results of the MT are corrected and entered into the TM of the translated document.
4. Thus the user receives:
Terminological dictionary;
translated document;
Corresponding to the translated TM document, which can be used in further work with documents of this kind.
Automatic design systems
CAD - software designed to create drawings, design and technological documentation, as well as 3D models. This list includes the most common CAx programs (CAD, CAM, CAE).
Speaking of automated translation, they usually mean programs that translate based on Machine Translation technology. However, there is another technology - Translation Memory, which, although not so widely known to Russian users, nevertheless has a number of advantages.
The rapid development of technological progress has led to an increase in the number technical devices, machines and other sophisticated technology, without which the life of a modern person is almost unthinkable. For example, the documentation for a European Airbus aircraft runs into tens of thousands of pages. According to a study conducted at the end of 2004 by the LISA association (LISA 2004 Translation Memory Survey), 42% of respondents translate about 1 million words a year, 24% of companies participating in the survey have an annual volume of translations of 1-5 million, 12 % translate from 5 to 10 million, the volume of translations of other companies - from 10 to 500 and more million words per year. In particular, most manufacturers today are not limited to their local market and are actively developing regional markets. At the same time, the localization of products, including the translation of the product description into the local language, is one of the prerequisites for entering a new market.
At the same time, although manufacturers regularly release new versions of their products - cars, excavators, computers and mobile phones, software, - not all of them are fundamentally different from previous models. Sometimes a new phone model is a slightly modified (or restyled) previous model. New versions sell better, so manufacturers have to update their products regularly. As a result, the documentation for each of these products is often 70-90% identical to that of the previous version.
Two factors - a large volume of documents requiring translation and their high repetition - served as an incentive to create the Translation Memory technology (abbreviated as TM, there is no generally accepted Russian translation of this term). The essence of TM technology can be figuratively conveyed in one phrase: "Do not translate the same text twice." In other words, Translation Memory is used to reuse previously made translations. This allows you to seriously reduce the time for preparing a translation, especially when working with texts that have a high degree of repetition.
Translation Memory technology is often confused with Machine Translation, which, of course, is also useful and interesting, but its description is not the purpose of this article. The use of TM technology increases the speed of translation by reducing the amount of mechanical work. However, it is important to note that TM does not translate for the translator, but is a powerful tool for reducing costs when translating repetitive texts.
The TM technology works on the principle of accumulating translation results: during the translation process, the original text and its translation are stored in the TM database. To facilitate the processing of information and comparison of different documents, the Translation Memory system breaks the entire text into separate pieces, which are called segments. These segments are most often offers, but other segmentation rules can be adopted. When a new text is loaded, the TM system performs segmentation and compares the source text segments with those already available in the connected translation memory. If the system can find a fully or partially matching segment, then its translation is displayed with an indication of the match in percent. Segments that differ from the stored text are highlighted. Thus, the translator only needs to translate new segments and edit overlapping ones.
As a rule, the threshold of matches is set at a level not lower than 75%, since if you set a lower percentage of matches, then the cost of editing the text will increase. Every change or new translation is saved in the TM, so there is no need to translate the same thing twice!
It is also important to constantly replenish the Translation Memory database, keeping in the database (or in the databases, if the translation is carried out on various topics) pairs of segments "source text - correct translation". This will significantly reduce the time needed to translate similar texts. In addition to reducing the complexity of translation, the TM system allows you to maintain the unity of terminology and style in all documentation.
The use of TM technology provides the translator with the following advantages:
- increase in labor productivity. Substituting even 80% of the matching segments from the translation memory can reduce the time spent on translation by 50-60%. As practice shows, it is much more efficient to edit an already finished translation than to translate again - "from scratch";
- unity of terminology and style in the presence of a translation base on the subject of the document being translated. This is especially important when translating highly specialized documentation;
- organizing the work of a team of translators with guaranteed quality of translation due to access to a common database of Translation Memory.
Separately, we note that in Western countries, where the Translation Memory technology has long become a de facto indispensable tool for a translator, the funds spent on creating a translation database are not considered as costs, but rather as investments in stable and high-quality work, which increases not only only profit, but also the value of the company itself.
Market of Translation Memory Systems
The undisputed leader in the market of Translation Memory systems are SDL-TRADOS programs. In the summer of 2005, the two largest developers of TM systems - SDL and TRADOS (software products under the TRADOS trademark are well known to many users) merged, and now they are releasing a joint product that is a trendsetter in the field of Translation Memory.
The new SDL-TRADOS system has enhanced (user-configurable) fuzzy matching functionality (search for matches in the translation memory), as well as tools for checking the quality of translated documents. The program checks spelling and protects the contents of memory blocks using encryption technology.
The system supports Word DOC and RTF, online help RTF, PowerPoint, FrameMaker, FrameMaker +SGML, FrameBuilder, Interleaf, QuickSilver, Ventura, QuarkXPress, PageMaker, SGML/HTML/XML, including HTML Help, RC (Windows Resource) , Bookmaster (DCF) and Troff. In addition to the SDL-TRADOS system, there are other TM systems on the IT market. French manufacturers are especially well represented.
The system of the French company Atril (www.atril.com) is called. Its developers first organized their own translation agency technical documentation, after which the idea of creating specialized software based on Translation Memory technology arose.
This is a standalone application with a systematic menu. The system can create TM databases, as well as terminology databases and connect dictionaries. The translation process is carried out in a special Project shell, where, when it is created, the file to be translated is attached, and additional settings: TM base, dictionaries, etc. The text is translated in a special table, where opposite each column of its original, you need to fill in the translation option. The benefits also include an additional function for translating files of different formats, which allows you to keep the original formatting of the file.