Sie alle kennen das Git-System. Zumindest haben Sie es gehört, das ist sicher. Entwickler, die das System verwenden, lieben es oder schimpfen es wegen seiner komplexen Benutzeroberfläche und Fehlern. Das Git-Versionskontrollsystem ist der De-facto-Industriestandard. Ein Entwickler hat vielleicht eine Meinung über die Vorteile von Mercurial, aber in den meisten Fällen muss man sich mit der Anforderung zufrieden geben, zu wissen, wie man Git verwendet. Wie jedes komplexe System verfügt es über viele nützliche und notwendige Funktionen. Allerdings erreicht nicht jeder die geniale Einfachheit, sodass die bestehende Implementierung Raum für Verbesserungen ließ.
Mit einfachen Worten: Eine knifflige Anwendung war schwierig zu bedienen. Deshalb haben sie im Labor des Massachusetts Institute of Technology Verbesserungen aufgegriffen und alle „Problemelemente“ herausgeschnitten (was für den einen ein Problem ist, kann für den anderen leicht ein Vorteil sein). Eine verbesserte und vereinfachte Version heißt Gitless. Es wurde anhand von 2400 Git-bezogenen Fragen entwickelt, die von der StackOverflow-Entwicklerseite stammen.
Was ist los mit Git?
Viele Benutzer haben sich darüber beschwert, dass Git eine neue Schnittstelle benötigt. Experten haben sogar ein Dokument geschrieben: Was ist los mit Git? Konzeptionelle Designanalyse. Autoren: S. Perez De Rosso und D. Jackson.Beispiel
git checkout< file >// alle Änderungen in einer Datei seit dem letzten Auschecken verwerfen git reset --hard // alle Änderungen in allen Dateien seit dem letzten Auschecken verwerfenDiese beiden Zeilen sind nur ein Beispiel dafür, wie sehr Git eine verbesserte Schnittstelle benötigte. Zwei verschiedene Befehle für dieselbe Funktion, mit einem Unterschied, dass einer für eine einzelne Datei und der andere für mehrere Dateien gilt. Ein Teil des Problems besteht auch darin, dass diese beiden Befehle nicht genau dasselbe bewirken.
Die meisten Git-Benutzer verwenden es für eine kleine Anzahl von Befehlen, und die verbleibenden wenigen kennen die Plattform auf einer tieferen Ebene. Es stellt sich heraus, dass im Grunde die Plattform dafür benötigt wird Basisfunktionen, und es bleibt eine große Schicht an Möglichkeiten für einen zu engen Kreis. Dies weist darauf hin, dass Git nicht ordnungsgemäß funktioniert.
Kurzer Vergleich der Grundfunktionen mit der Vorgängerversion
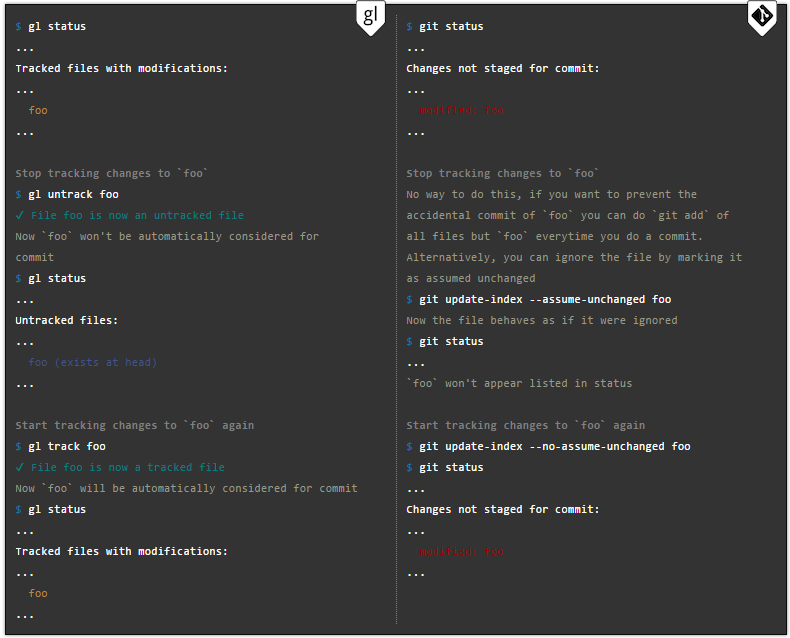
Eines der auffälligsten Merkmale von Gitless ist, dass es eine Funktion namens Staging ignoriert. Es ermöglicht Ihnen, einzelne Teile der Datei zu speichern. Praktisch, kann aber zu problematischen Situationen führen. Der Hauptunterschied zwischen dieser und der Stashing-Funktion besteht darin, dass letztere Änderungen aus dem Arbeitsbereich verbirgt.Die Stashing-Funktion verbirgt die grobe Arbeit im Arbeitsverzeichnis – die nachverfolgten Dateien, die geändert wurden, und speichert alles mit ausstehenden Änderungen auf dem Stapel. Alle Änderungen können später bei Bedarf übernommen werden. Dies ist erforderlich, wenn Sie an einem Zweig arbeiten und dort alles in einem chaotischen Zustand ist, Sie aber dringend zu einem anderen Zweig wechseln müssen. Sie möchten im angehaltenen Zustand keinen Code mit teilweise erledigter Arbeit im ersten Zweig auschecken.
Die Staging-Funktion indiziert an einer Datei vorgenommene Änderungen. Wenn Sie Dateien als bereitgestellt markieren, weiß Git, dass Sie sie bereitgestellt haben.
In Gitless gibt es kein Konzept zum Verstecken. Stellen Sie sich die folgende Situation vor. Sie sind mitten in der Entwicklung eines Projekts und müssen zu einem anderen Zweig wechseln, haben Ihre halbfertige Arbeit aber noch nicht hochgeladen. Die Stashing-Funktion übernimmt die von Ihnen vorgenommenen Änderungen und speichert sie im ausstehenden Stapel, den Sie später wiederherstellen können.
Der Autor des Gitless-Leitfadens berichtet, dass das Problem beim Wechsel zwischen Zweigen auftritt. Es kann schwierig sein, sich daran zu erinnern, welche Vorräte sich wo befinden. Der Clou an all dem ist, dass die Funktion nicht hilft, wenn Sie gerade eine Zusammenführung durchführen, die widersprüchliche Dateien enthält. Dies ist die Meinung von Perez de Rosso.
Dank Gitless ist dieses Problem gelöst. Zweige sind im Verhältnis zueinander völlig autonom geworden. Dies erleichtert die Arbeit erheblich und ermöglicht es Entwicklern, die Verwirrung zu vermeiden, die durch den ständigen Wechsel zwischen Aufgaben entsteht.
Änderungen speichern
Gitless verbirgt den Stufenbereich im Allgemeinen, was den Prozess für den Benutzer transparenter und weniger kompliziert macht. Es gibt viel flexiblere „Commit“-Befehle zum Lösen von Problemen. Darüber hinaus ermöglichen sie Ihnen Aktionen wie das Hervorheben von Codesegmenten für den Commit.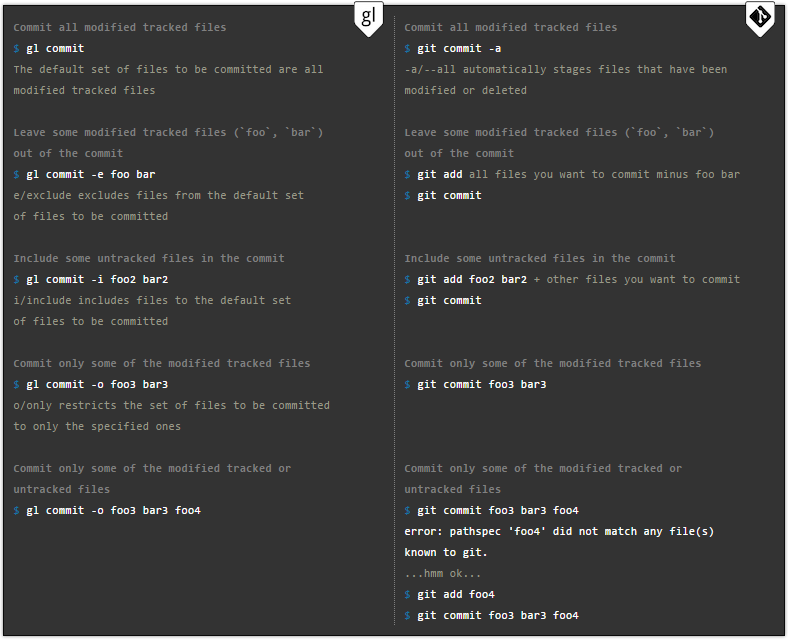
Darüber hinaus können Sie die Klassifizierung jeder Datei in Werte ändern: nachverfolgt, nicht nachverfolgt oder ignoriert. Es spielt keine Rolle, ob diese Datei im Header vorhanden ist oder nicht.
Verzweigte Entwicklungsprozesse
Unbedingt zu verstehen neue Version, Idee: Niederlassungen in Gitless wurden zu völlig unabhängigen Entwicklungslinien. Jeder von ihnen behält seine Arbeitsversion der Dateien getrennt von den anderen. Keine Überschneidungen oder Probleme. An jedem Punkt, an dem Sie zu einem anderen Zweig wechseln, werden die Inhalte Ihres Arbeitsbereichs gespeichert und die für den Zielzweig relevanten Dateien wiederhergestellt. Die Dateiklassifizierung bleibt ebenfalls erhalten. Wenn eine Datei in zwei separaten Zweigen unterschiedlich klassifiziert ist, berücksichtigt Gitless dies.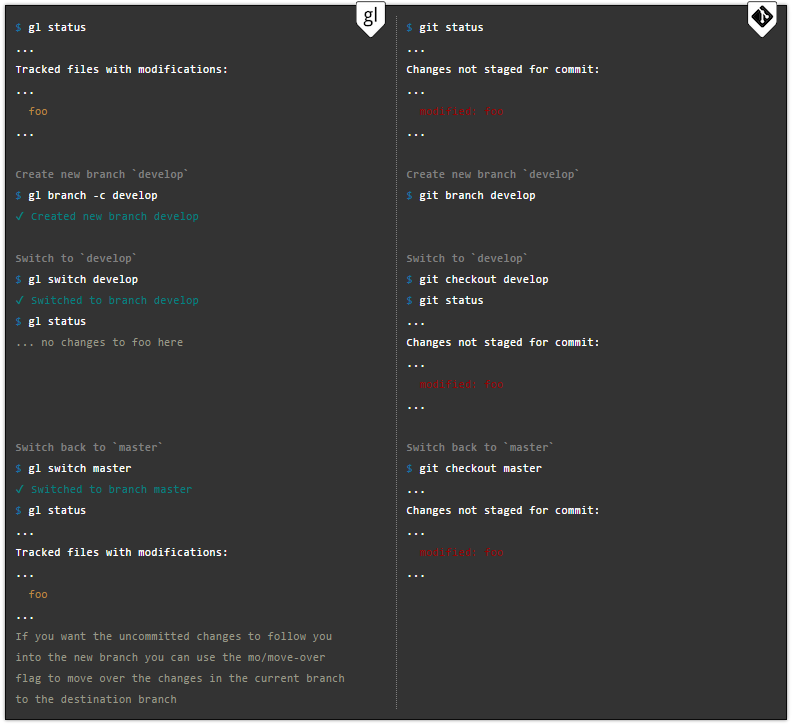
Einfach ausgedrückt: rein Gitless-Versionen Sie müssen nicht auf nicht festgeschriebene Änderungen achten, die mit Änderungen im Zielzweig in Konflikt stehen.
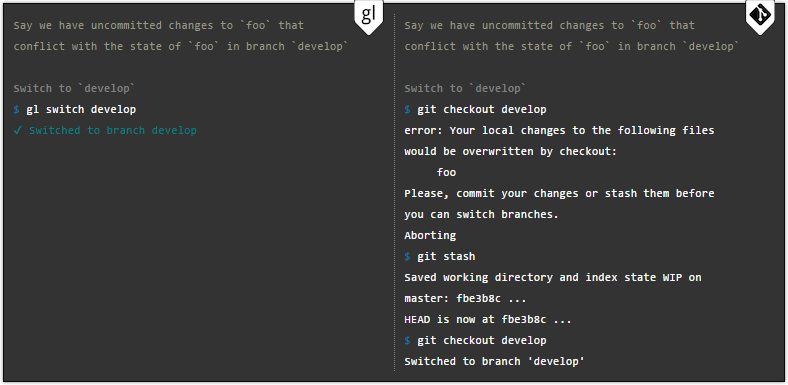
Sie können die Konfliktlösung auch verzögern, wenn Sie sich mitten in einer Zusammenführung oder Fusion befinden. Der Konflikt bleibt bestehen, bis Sie zurückwechseln.
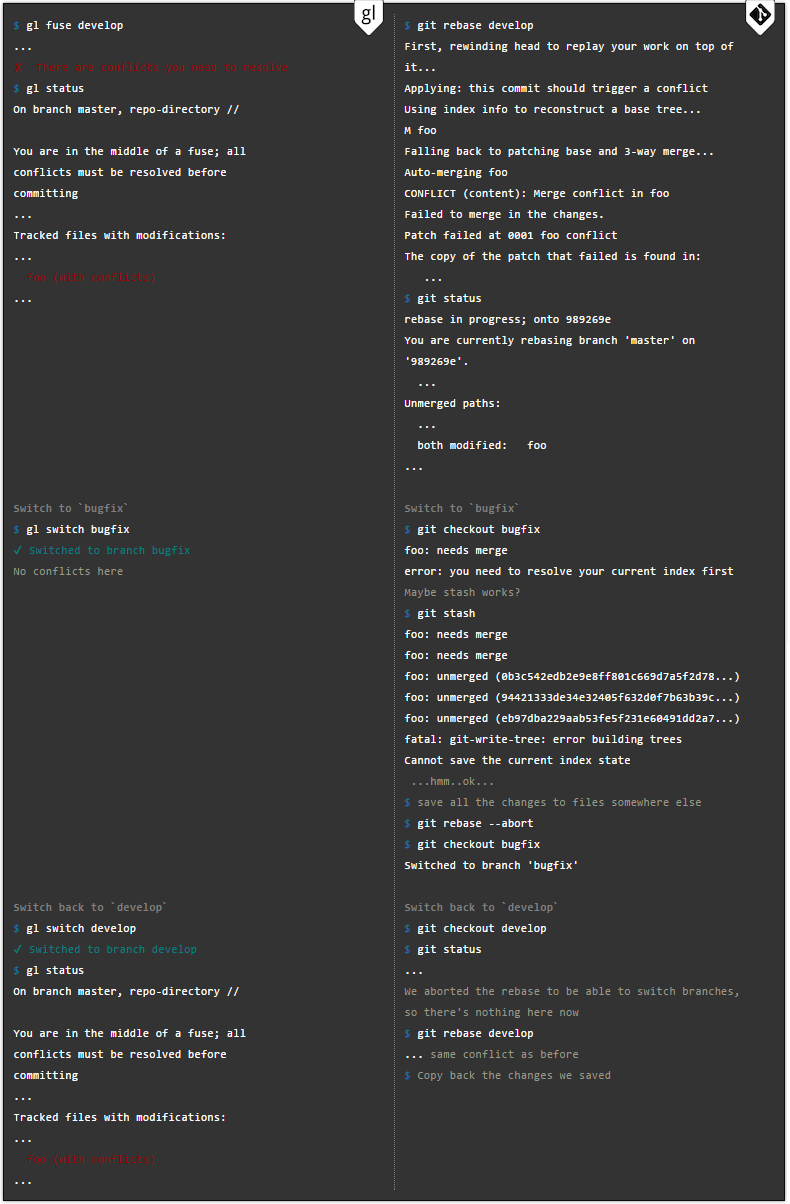
Arbeiten mit Remote-Repositorys
Dabei erfolgt die Synchronisierung mit anderen Repositories in beiden Programmen auf die gleiche Weise.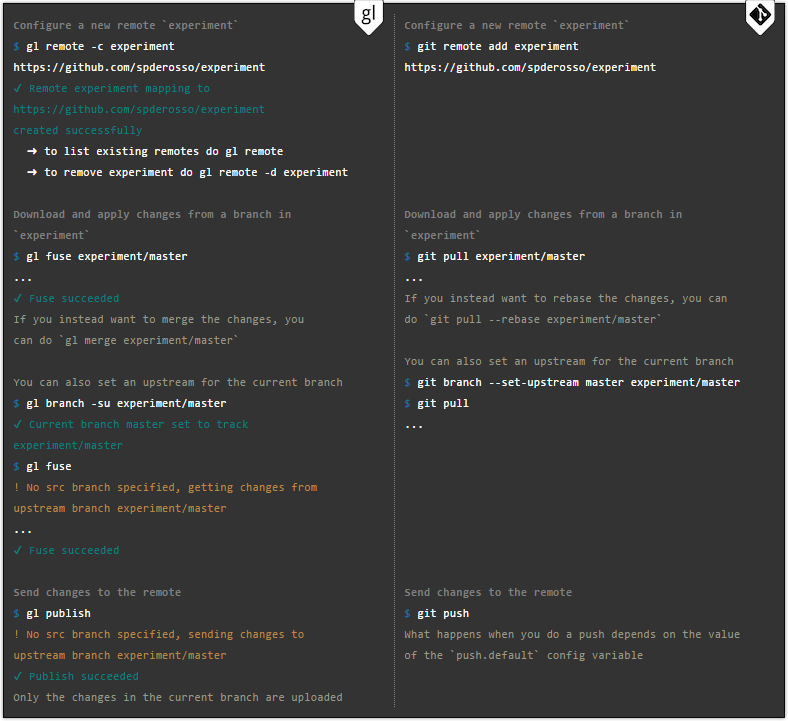
Ein weiterer Vorteil der neuen Version ist die Möglichkeit, ohne Codeverlust auf die alte Version umsteigen zu können. Gleichzeitig wissen Ihre Kollegen möglicherweise nicht einmal, dass Sie andere Software verwenden.
Den Leitfaden zur Arbeit mit Gitless können Sie auf der offiziellen Website der Anwendung lesen. In der Dokumentation wird Folgendes beschrieben: So erstellen Sie ein Repository und speichern Änderungen. wie man mit Zweigen arbeitet; wie man Tags verwendet, mit Remote-Repositorys arbeitet.
Was ist das Ergebnis
Das Ergebnis ist eine Anwendung, die die Funktionalität von Git beibehält, aber gleichzeitig für Entwicklungsteams einfacher zu erlernen und zu verwenden ist. Tatsächlich gab es bereits vor Gitless Versuche, Git zu verbessern. Aber laut Philip Guo (er ist Assistenzprofessor für Kognitionswissenschaft an der University of California San Diego) erreichte diese Version zum ersten Mal die Ziele, die Schnittstelle zu transformieren und tatsächlich große Probleme zu lösen.Das Projekt verwendete strenge Methoden zur Erstellung Software. Dies ist notwendig, um die Mängel in einem der am weitesten verbreiteten Softwareprojekte der Welt einzugrenzen. In der Vergangenheit haben viele Benutzer sowohl für als auch gegen Git lächerliche Argumente vorgebracht, aber keines davon basierte auf einem wissenschaftlichen Ansatz.
Am Beispiel von Gitless wird deutlich, dass der Vereinfachungsansatz auch auf andere komplexe Systeme anwendbar ist. Zum Beispiel, Google-Posteingang und Dropbox.
Bei der Arbeit an einem Projekt stoßen die Teilnehmer häufig auf Synchronisierungs- und Dateiverlaufsprobleme, bei deren Lösung Versionskontrollsysteme (VCS) helfen. Der Zweck dieser Artikelserie besteht darin, den Leser mit den Prinzipien der Arbeit des VCS vertraut zu machen und eines davon, nämlich Git, im Detail zu betrachten. Warum Git? Dieses System erfreut sich in letzter Zeit zunehmender Beliebtheit und seine Bedeutung für freie Software (und insbesondere für das GNU/Linux-Projekt) kann nicht hoch genug eingeschätzt werden.
Wir sind konsequent allgemein gesagt Wir analysieren die Eigenschaften von Steuerungssystemen, sprechen über ihre Architektur und die Hauptmerkmale der jeweiligen Anwendung. Darüber hinaus werden wir die aktuell vorhandenen Schnittstellen für die Arbeit mit Git überprüfen.
Der Autor verzichtet bewusst auf die Terminologie von Funktionen, Tasten und anderen Feinheiten, um Ihnen das Bild klar, übersichtlich und allgemein darzustellen. In diesem Artikel wird davon ausgegangen, dass der Leser mit Unix-ähnlichen Betriebssystemen (OS) vertraut ist und dies auch getan hat Grundwissen im Bereich Algorithmik und Informatik im Allgemeinen.
In den folgenden Materialien werden wir uns mit der Struktur und Philosophie von Git, den Besonderheiten dieses Systems und den Feinheiten der praktischen Arbeit damit befassen. Der Zyklus endet mit einem Artikel über die Interaktion von Git mit anderen VCS (wie Subversion, CVS, Mercurial usw.).
2. Git ist...
Git ist ein verteiltes Dateiversionskontrollsystem. Der Programmcode ist hauptsächlich in C geschrieben. Das Projekt wurde 2005 von Linus Torvalds ins Leben gerufen, um die Entwicklung des Linux-Kernels zu verwalten, und ist wie GNU/Linux freie Software (Software). Nutzung durch Dritte unterliegt der GNU GPL Version 2-Lizenz. Kurz gesagt kann diese Vereinbarung als freie Code-Software beschrieben werden, die offen entwickelt werden muss, d. h. Jeder Programmierer hat das Recht, das Projekt in jeder Phase weiter zu verbessern. Während seiner kurzen Existenz dieses System wurde von vielen führenden Entwicklern eingeführt. Git wird in so bekannten Linux-Community-Projekten wie Gnome, GNU Core Utilities, VLC, Cairo, Perl, Chromium, Wine verwendet.
3. Versionskontrollsysteme
Versionskontrollsysteme (Version Control Systems) sind Software, die dazu dient, die Arbeit mit dem Verlauf einer Datei (oder einer Gruppe von Dateien) zu automatisieren, Änderungen zu überwachen, Daten zu synchronisieren und ein sicheres Projekt-Repository zu organisieren. Kurz gesagt besteht der Hauptzweck von Versionskontrollsystemen darin, die Arbeit mit sich ändernden Informationen zu erleichtern. Lassen Sie uns die allgemeine Sicht auf die Entwicklung anhand eines Beispiels analysieren.
Angenommen, Sie entwickeln ein bestimmtes Projekt, mehrere Programmierabteilungen und Sie sind der Koordinator (oder Leiter). In Bezug auf das Steuerungssystem, sei es ein Server (wenn es sich um ein zentrales System handelt) oder eine lokale Maschine, ist jeder Projektentwickler nur durch Zugriffsrechte zum Ändern und/oder Lesen von Dateiversionen eingeschränkt dieses Repository. Sie können die Daten jederzeit auf die von Ihnen benötigte Version zurücksetzen. Als Koordinator können Sie den Zugriff auf bestimmte Benutzer beschränken, um die Dateiversion zu aktualisieren. Es bietet außerdem eine Schnittstelle zur Überwachung und Suche nach Dateiversionen. Sie können beispielsweise eine Abfrage erstellen: „Wo und wann wurde dieser Code geändert?“.
Das System geht von einer sicheren Datenspeicherung aus, d.h. Jeder darin gespeicherte Block hat viele Klone. So können Sie beispielsweise im Falle einer Beschädigung einer Datei diese zeitnah durch eine Kopie ersetzen. Um das Volumen der Projektdaten zu reduzieren, wird häufig die Deltakomprimierung verwendet – eine Art der Speicherung, bei der nicht die Versionen der Datei selbst gespeichert werden, sondern nur Änderungen zwischen aufeinanderfolgenden Revisionen.
4. Unterschiede in verteilten Versionskontrollsystemen
Verteilte Versionskontrollsysteme sind VCS, deren Hauptparadigma die Lokalisierung der Daten jedes Projektentwicklers ist. Mit anderen Worten: Wenn im zentralisierten VMS alle Aktionen auf die eine oder andere Weise vom zentralen Objekt (Server) abhängen, behält im verteilten VMS jeder Entwickler seinen eigenen Versionszweig des gesamten Projekts. Der Vorteil eines solchen Systems besteht darin, dass jeder Entwickler die Möglichkeit hat, unabhängig zu arbeiten und von Zeit zu Zeit Zwischenversionen von Dateien mit anderen Projektteilnehmern auszutauschen. Betrachten wir diese Funktion und setzen wir das vorherige Beispiel fort.
Jeder Entwickler auf dem Computer verfügt über ein eigenes lokales Repository – einen Ort, an dem Dateiversionen gespeichert werden. Die Arbeit mit Projektdaten wird auf Ihrem implementiert lokales Repository, und dafür ist es nicht notwendig, den Kontakt mit den übrigen (auch wenn die wichtigsten) Entwicklungszweigen aufrechtzuerhalten. Die Kommunikation mit anderen Repositorys ist nur erforderlich, wenn Versionen von Dateien aus anderen Zweigen geändert/gelesen werden. Gleichzeitig legt jeder Projektteilnehmer die Rechte seines eigenen Speichers zum Lesen und Schreiben fest. Somit sind alle Zweige im verteilten VCS einander gleich und der Hauptzweig wird vom Koordinator ausgewählt. Der einzige Unterschied zum Hauptzweig besteht darin, dass Entwickler mental zu ihm aufschauen.
5. Hauptmerkmale und Features von Git
Es ist erwähnenswert, dass das System, wenn es nicht für Aufsehen gesorgt hat, die SUV-Community mit seiner Neuheit ein wenig aufgewühlt und einen neuen Entwicklungspfad eröffnet hat. Git bietet flexible und benutzerfreundliche Tools zur Pflege des Projektverlaufs.
Eine Besonderheit von Git besteht darin, dass die Arbeit an Projektversionen möglicherweise nicht in chronologischer Reihenfolge erfolgt. Die Entwicklung kann in mehreren parallelen Zweigen erfolgen, die jederzeit während der Entwicklung zusammengeführt und aufgeteilt werden können.
Git ist ein recht flexibles System und sein Anwendungsbereich beschränkt sich nicht nur auf die Entwicklung. Beispielsweise können Journalisten, Autoren technischer Literatur, Administratoren und Universitätsprofessoren es durchaus für ihre Tätigkeit nutzen. Zu diesen Aufgaben gehört die Versionskontrolle aller Dokumentationen, Berichte und Hausaufgaben.
Lassen Sie uns die Hauptunterschiede zwischen Git und anderen verteilten und zentralisierten VMS hervorheben.
Git-Architektur
SHA1 (Secure Hash Algorithm 1) ist ein kryptografischer Hashing-Algorithmus. Jede Datei in Ihrem Git-Projekt besteht aus einem Namen und einem Inhalt. Der Name besteht aus den ersten 20 Datenbytes und ist deutlich in vierzig Zeichen im Hexadezimalformat geschrieben. Dieser Schlüssel wird durch Hashing des Inhalts der Datei erhalten. So können wir beispielsweise durch den Vergleich zweier Namen mit nahezu 100-prozentiger Sicherheit sagen, dass sie den gleichen Inhalt haben. Außerdem sind die Namen identischer Objekte in verschiedenen Zweigen (Repositorys) gleich, sodass Sie Daten direkt bearbeiten können. gute Ergänzung Zu dem oben Gesagten trägt auch die Tatsache bei, dass man mit dem Hash den Schaden an Dateien genau bestimmen kann. Indem wir beispielsweise den Hash des Inhalts mit dem Namen vergleichen, können wir ziemlich genau sagen, ob die Daten beschädigt sind oder nicht. Unter Name verstehen wir außerdem den Namen der Datei und die Zeichenfolge wird als SHA1-Hash bezeichnet.
Erwähnenswert sind die sogenannten Kollisionen. „Es ist ziemlich genau, den Schaden zu bestimmen“ bedeutet, dass es solche Dateien mit unterschiedlichem Inhalt gibt, deren SHA1-Hash derselbe ist. Die Wahrscheinlichkeit solcher Kollisionen ist sehr gering und vorläufige Einschätzung entspricht 2 hoch -80 (~ 10 hoch -25). Eine genaue Schätzung gibt es nicht, denn dieser Moment Der Weltgemeinschaft gelang es nicht, dieses kryptografische Schema effektiv zu entschlüsseln.
Git-Objekte
Das Arbeiten mit Dateiversionen in Git kann mit den üblichen Vorgängen auf verglichen werden Dateisysteme Autsch. Die Struktur besteht aus vier Objekttypen: Blob, Tree, Commit und References; einige davon wiederum sind in Unterobjekte unterteilt.
Blob (Binary Large Object) ist ein Datentyp, der nur den Inhalt einer Datei und seinen eigenen SHA1-Hash enthält. Blob ist das wichtigste und einzige Speichermedium in der Git-Struktur. Es ist möglich, eine Parallele zwischen diesem Objekt und Inodes in Dateisystemen zu ziehen, da ihre Struktur und ihr Zweck sehr ähnlich sind.
Baum
- eigener SHA1-Hash;
- SHA1-Hash von Blobs und/oder Bäumen;
- Zugriffsrechte von Unix-Systemen;
- symbolischer Name des Objekts (Name für interne Benutzung im System).
Im Kern ist ein Objekt analog zu einem Verzeichnis. Es definiert die Hierarchie der Projektdateien.
Begehen– ein Datentyp, der Folgendes enthält:
- eigener SHA1-Hash;
- Link zu genau einem Baum;
- ein Link zum vorherigen Commit (es können mehrere davon vorhanden sein);
- der Name des Autors und die Zeit, zu der der Commit erstellt wurde;
- der Name des Committers (Commiter ist die Person, die das Commit auf das Repository angewendet hat, er kann vom Autor abweichen) und die Zeit, zu der das Commit angewendet wurde;
- beliebiges Datenelement (ein Block kann dazu verwendet werden). elektronische Unterschrift oder zum Beispiel um Änderungen an einem Commit zu erklären).
Dieses Objekt dient dazu, einen Snapshot (Version) einer Gruppe von Dateien zu einem bestimmten Zeitpunkt zu speichern. Sie können ihn mit einem Prüfpunkt vergleichen. Commits können kombiniert (Merge), verzweigt (Branch) oder beispielsweise eine lineare Struktur festlegen und so die Hierarchie der Projektversionen widerspiegeln.
Referenz ist ein Datentyp, der einen Verweis auf eines der vier Objekte (Blob, Tree, Commit und References) enthält. Sein Hauptzweck besteht darin, direkt oder indirekt auf ein Objekt zu verweisen und ein Synonym für die Datei zu sein, auf die es verweist. Dadurch erhöht sich das Verständnis für die Projektstruktur. Es ist sehr umständlich, mit einem bedeutungslosen Zeichensatz im Namen zu arbeiten, während der Link im Gegensatz zum SHA1-Hash benannt werden kann, da dies für den Entwickler bequemer ist.
Links wiederum können in eine Reihe von Unterobjekten unterteilt werden, die einige Unterschiede aufweisen: Zweig, Tag. Betrachten wir sie.
Zweigstelle (Leiter, Zweigstelle)– ein symbolischer Link, der auf den letzten Commit im Commit-Verlauf eines bestimmten Zweigs verweist und den SHA1-Hash des Objekts speichert. Ist der Datentyp von Journaled-File-Systemen. Dieser Objekttyp ist nicht in Git selbst definiert, sondern wird vom Betriebs- und Dateisystem geerbt. Ein Zweig wird als Synonym für die Datei verwendet, auf die er verweist, d. h. Mit Git können Sie direkt darauf zugreifen. Sie können es sich leisten, nicht darüber nachzudenken, ob Sie mit uns zusammenarbeiten letzte Version oder nicht.
Schild ist ein Datentyp, der sich im Gegensatz zu Branches immer auf dasselbe Objekt vom Typ Blob, Tree, Commit oder Tag bezieht. Es kann wiederum in leicht (Light-Tag) und Heavy oder Annotated (Annotated-Tag) unterteilt werden. Das Light-Tag unterscheidet sich, abgesehen von der Unveränderlichkeit des Links, nicht von gewöhnlichen Zweigen, d. h. enthält nur den SHA1-Hash des Objekts, auf das es sich bezieht. Ein mit Anmerkungen versehenes Tag besteht aus zwei Teilen:
- der erste Teil enthält seinen eigenen SHA1-Hash;
- Der zweite Teil besteht aus:
- SHA1 des Objekts, auf das das mit Anmerkungen versehene Tag zeigt;
- der Typ des angegebenen Objekts (Blob, Baum, Commit oder Tag);
- der symbolische Name des Tags;
- Datum und Uhrzeit der Erstellung des Tags;
- Name und E-Mail-Adresse des Tag-Erstellers;
- ein beliebiges Datenelement (dieser Block kann für eine elektronische Signatur oder zur Erläuterung eines Tags verwendet werden).
Mit anderen Worten: Ein Projekt in Git ist eine Sammlung von Blobs, die durch ein Netzwerk aus Bäumen verbunden sind. Die resultierende hierarchische Struktur kann sich je nach Zeit in Form von Commits – Versionen – widerspiegeln. Um deren Struktur zu verstehen, enthält Git Objekte wie Links. Mit Ausnahme von Aktionen mit Links werden fast alle Arbeiten mit Systemobjekten von innen heraus so weit wie möglich automatisiert. Ausgehend vom Verknüpfungsmechanismus kommen wir zu der folgenden Idee – die Arbeit an Dateigruppen. Laut dem Autor ist die Idee der Schlüssel zur Philosophie von Git. Nachdem Sie beispielsweise eine Operation für einen bestimmten Commit festgelegt haben, wird dieser rekursiv seinen Teil entlang des Baums ausarbeiten, auf den er sich bezieht. Als Erweiterung der allgemeinen Ansicht „Aktion für jede Datei“ vereinfacht die Innovation die Implementierung und Herangehensweise des Programmierers an alltägliche VCS-Aufgaben, wie das Zusammenführen/Aufteilen von Zweigen, und automatisiert den Prozess erneut rekursiv. Dieser Ansatz ist leicht verständlich, funktioniert schnell und ist flexibel in der Zielerreichung. Viele dieser Funktionen werden durch die Unix-orientierte Natur des Systems erreicht; Bei den Standardgeräten greift Git auf die bereits im Betriebssystem vorhandenen Lösungen zurück.
Lassen Sie uns den Zeitpunkt der Datenspeicherung klären. Inhalt von Dateien verschiedene Versionen nimmt in der Chronologie ziemlich viel Speicher ein. So wird beispielsweise in einem Projekt mit zwanzig Dateien mit zwanzig Versionen das Archiv 20-mal mehr wiegen (vielleicht in der Größenordnung von hundert Megabyte), aber was passiert, wenn die Anzahl beider Dateien zehnmal so groß ist (wie es scheint). nicht viel sein)? Die Größe des belegten Speicherplatzes erhöht sich um das Hundertfache (d. h. etwa 1 GB). IN echte Aufgaben Die Wachstumsrate des belegten Speichers ist nicht linear von der Zeit abhängig. Zur Lösung dieses Problems gibt es mehrere Optimierungen:
- jedes Git-Objekt wird als reguläres Archiv (tar.gz) gespeichert;
- Die sequentielle Deltakomprimierung wird auf die gesamte Dateihierarchie angewendet.
Nehmen wir ein Beispiel.
Sie haben eine dreijährige Geschichte Ihres Projekts, es umfasst etwa tausend Dateien und hundert Versionen. Wenn Sie irgendwann am meisten Kontakt benötigen frühe Version, muss Git den gesamten Verlauf der Datei delta-entpacken. Enttäuschenderweise kann dieser Vorgang bis zur Mittagszeit dauern. Git schlägt vor, sogenannte Breakpoints zu machen, d.h. Speichern Sie eine wöchentlich archivierte Datei nach einer bestimmten Anzahl von Versionen, die wir als Komprimierungstiefe bezeichnen. Dann wird in unserem Beispiel der gesamte Verlauf auf eine vorgegebene Anzahl von Delta-Komprimierungen eingegrenzt, die entpackt werden, sodass Sie jede Version in der Chronologie betrachten können. Beachten Sie, dass die Delta-Komprimierung am besten für die Verwendung bei einigen Objekttypen geeignet ist, die der Hierarchie am nächsten stehen. Dazu muss das Repository entsprechend nach Typ und Größe sortiert werden. Diese in diesem Absatz beschriebene Reihe von Vorgängen wird von der Funktion git-repack (und git-gc, das sie enthält) ausgeführt.
Zweige zusammenführen und aufteilen
Diese Frage ist sehr zeitaufwändig und gesättigt, weshalb wir die Konzepte der Verschmelzung und Trennung nur allgemein vorstellen. Schauen wir uns das Beispiel noch einmal an.
Stellen Sie sich den Moment der Projektentwicklung vor, in dem das Hauptziel die Geschwindigkeit des Programms ist. Eine der möglichen taktischen Lösungen besteht darin, die Entwickler in zwei Gruppen aufzuteilen, die jeweils das gleiche Problem lösen. In diesem Fall sollte der Zweig der Projektgeschichte aufgeteilt werden. Dieser Vorgang wird als Verzweigung bezeichnet. Beim Verzweigen eines Zweigs wird lediglich eine Kopie davon erstellt, die später über einen eigenen Verlauf verfügt.
Angenommen, wir haben zwei bereits abgeschlossene Ergebnisse derselben Aufgabe erhalten, an der zwei Gruppen von Programmierern gearbeitet haben. Wie können wir sein? Sehen Sie, wessen Code schneller und zuverlässiger ist? Es ist zu einfach, aber nicht immer die beste Lösung. Gute Entscheidung- Teilen Sie sie mit ein wenig Verständnis für den Code und die Dateien in Unteraufgaben oder Codeblöcke auf. Und erst dann, um die Starken zu offenbaren schwache Seiten diese Stücke. Diese Option ist natürlich nur dann geeignet, wenn Sie im Vorhinein vorhergesehen haben, dass Sie alle diese Partikel später zusammen sammeln können. Der Fall, dass Sie selbst den Code entwickeln, einige Fehler verbessern und beheben, entspricht dem obigen Beispiel. Dieser Prozess Das Kombinieren zweier Ganzzahlen zu einer wird als Zusammenführung bezeichnet. Der Prozess der Zusammenführung zweier Versionen ist der Schlüsselmoment des Projektmanagements. Wie dem auch sei, Sie sollten die automatisierte Ausführung dieses Vorgangs vermeiden. Besonderheit Git ist am zuverlässigsten und hübschesten der schnelle Weg Lösung des Verzweigungsproblems.
Zu den Vorteilen des Systems gehören:
- Unix-orientiert.
- Ideologische Konsequenz (Wenn man die Regeln für die Nutzung des Systems befolgt, ist es sehr schwierig, in eine aussichtslose Situation zu geraten oder etwas zu bekommen, mit dem man nicht gerechnet hat).
- Hohe Leistung (das ist einer der offensichtlichsten Vorteile des Systems, dessen Preis „ideologische Konsistenz“ und „Unix-Orientierung“ ist).
- Git-Integration mit VMS von Drittanbietern wie Subversion, Mercurial, ...
- Verwalten einer Gruppe von Dateien (das System muss Änderungen in jeder Datei nicht einzeln berücksichtigen, es merkt sich alle Änderungen im gesamten Projekt und wenn Sie plötzlich einzelne Änderungen verfolgen müssen, zeigt es genau den Teil an, der mit dieser Datei verknüpft ist ).
- Zusammenführungsvorgang (die am stärksten automatisierte Implementierung einer komplexen Aufgabe).
Zu den Nachteilen zählen:
- Unix-zentriert (beachten Sie das Fehlen einer ausgereiften Git-Implementierung auf Nicht-Unix-Systemen).
- Die Notwendigkeit, den Befehl git-gc regelmäßig auszuführen (packt Gruppen von Dateien und entfernt diejenigen, die nicht verknüpft sind).
- Hashing-Kollisionen (Zusammentreffen von SHA1-Hashes verschiedener Dateien).
6. Git-Schnittstellen
„Wie viele Menschen, so viele Meinungen.“ Versuchen wir, eine Reihe von Schnittstellentypen für die Arbeit mit dem System zu identifizieren. Für bestimmte Zwecke ist jede der folgenden Anwendungsarten auf ihre Art besser.
Für Leute, die nicht viel entwickeln, für „Konservative“ – diejenigen, die „Schaltflächen und Kontrollkästchen“ lieben und sich bewusst vor dem übermäßigen Aufwand schützen möchten, sich Funktionen, Tasten und viele Feinheiten zu merken, ist die Stiloption TortoiseGit oder Git Extensions besser geeignet - einfache Schnittstellen. Sie ermöglichen die Bedienung vorwiegend mit der Maus und das Arbeiten im gewohnten Windows-Betriebssystem.
Genau die entgegengesetzte Art von Schnittstelle. Für Programmierer, die ständig mit Mitarbeitern interagieren müssen, um typische Probleme der Codesteuerung zu lösen, für Personen, die es gewohnt sind, in Unix-ähnlichen Systemen über ein Terminal zu arbeiten, ist die Konsolenansicht von Anwendungen am besten geeignet. Sie sind genauso einfach zu bedienen, etwas schneller und funktionaler, aber sie müssen sich die Zeit nehmen, um herauszufinden, wie man sie benutzt.
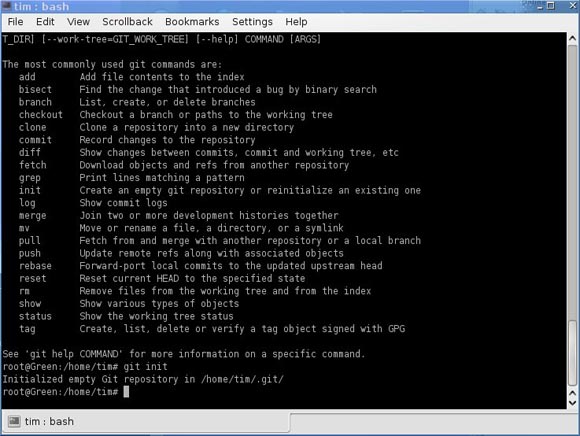
Es lässt sich auch eine dritte Art von Schnittstellen unterscheiden – eine Mischung aus den ersten beiden. Diese. Sie haben eine Konsolenanwendung, wie eine native Git-Shell. Sie können eine Reihe zusätzlicher Dienstprogramme wie Gitk oder QGit verwenden, um Bäume anzuzeigen, die Versionshierarchie und Unterschiede zwischen Versionen einfacher zu erkennen und die benötigten Objekte zu finden.
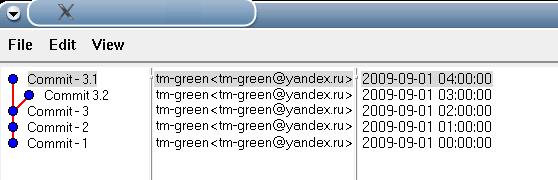
7. Fazit
Die Leser können sich also bereits vorstellen, wie sie funktionieren moderne Systeme Versionskontrolle. Darüber hinaus haben wir die Architektur eines der beliebtesten Systeme überprüft – Git. Im nächsten Artikel werden wir versuchen, einige seiner Funktionen in der Praxis kennenzulernen – wir werden die Funktionen und Tasten dafür betrachten. Der Artikel enthält eine Reihe anschaulicher Beispiele für die Pflege des Dateiverlaufs sowie die Philosophie verteilter Systeme. Der Autor wird versuchen, den Lesern zu zeigen, wie man Git richtig verwendet, und wird sich einige davon ansehen typische Fehler Nutzung dieses SUV.
Ich habe vor kurzem gebraucht, um mehreren meiner Mitarbeiter, die gerade erst das Programmieren lernen und versuchen zu arbeiten, die Grundlagen von Git beizubringen. Als ich im Internet nach Artikeln für Anfänger suchte, stieß ich auf die Tatsache, dass es in den meisten davon um die Verwendung von Konsolen-Git oder um dessen Notwendigkeit und Vorteile gegenüber anderen ähnlichen Systemen geht. Ein Anfänger ist in all diesen Dingen normalerweise nicht sehr stark. Ich glaube, dass er, zunächst einmal, und es ist nicht notwendig, das alles zu wissen. Schließlich können Sie Git für Ihre Projekte nutzen und parallel zum Programmieren alle seine Reize erlernen. Aber,Ich empfehle Ihnen dringend, diesen Artikel als Einführungsartikel zu verstehen und sich in Zukunft eingehender mit Git zu befassen..
Im Allgemeinen befindet sich unter dem Schnitt ein Artikel zur Verwendung SmartGit und BitBucket kann Ihr Leben als unerfahrener Entwickler verbessern.
M kleiner Plan, was wir tun werden:
- Erstellen eines Repositorys auf Bitbucket.
- Klonen des Repositorys (Hinzufügen zu SmartGit).
- Bildung von Ausschüssen.
- Änderungen verwerfen.
- Filialen erstellen.
- Verschieben von Branches in ein Remote-Repository (Hochladen von Branches auf einen Remote-Server).
- Zweige zusammenführen.
Gehen. Das Erstellen eines Repositorys ist sehr einfache Aufgabe. Wir werden dafür BitBucket verwenden, daher müssen Sie dort über ein Konto verfügen. Klicken Sie nach der Registrierung auf die Schaltfläche „Erstellen“ und füllen Sie die erforderlichen Felder aus. Klonen Sie das Repository mit SmartGit. Nehmen wir einen Link zu unserem Repository.
Nun starten wir SmartGit, wählen „Projekt“ – „Klonen“ (oder Strg + Alt + O) und füllen die erforderlichen Felder aus:
Das System fragt Bitbucket nach Ihrem Benutzernamen und Passwort:
Im nächsten Fenster stehen zwei Klonoptionen zur Verfügung: „Submodule einschließen“ und „Alle Köpfe und Tags abrufen“. Git ermöglicht die Speicherung einzelner Anwendungsmodule in unterschiedlichen Repositories. Wenn Sie die Option „Submodule einschließen“ aktivieren, lädt SmartGit automatisch alle Module. Wenn Sie die Option „Alle Köpfe und Tags abrufen“ aktivieren, lädt SmartGit alle Zweige und Tags für dieses Repository herunter, nachdem der Projektordner erstellt wurde:
Das nächste Fenster zeigt den Namen des Projekts in SmartGit:
Wenn Sie geklont haben leeres Repository(wie in diesem Artikel) sehen Sie das folgende Fenster:
Fortfahren. Lasst uns ein Komitee gründen. Was ist ein Komitee? Dies ist ein Commit. Bei jedem Commit „merkt“ sich, was genau Sie geändert haben, und Sie können jederzeit den vorherigen Zustand der Dateien wiederherstellen. Ich empfehle Ihnen, nach jeder wesentlichen Änderung, beispielsweise der Behebung eines Fehlers in einer Funktion, einen Commit durchzuführen. Um einen Commit zu erstellen, müssen Sie etwas im Projekt ändern. Fügen Sie dem Projektordner einige Dateien hinzu:
Jetzt können wir unsere Projektänderungen in SmartGit sehen:
Wählen Sie beide Dateien aus und klicken Sie zuerst auf „Stufe“ und dann auf „Übernehmen“. Warum müssen Sie auf „Bühne“ klicken? Die Schaltfläche „Stufe“ fügt die ausgewählten Dateien dem aktuellen Index hinzu. Wenn Sie ein Commit für zwei Dateien erstellen möchten und diese geändert haben, sagen wir, bis zu 5, wählen Sie einfach diese beiden Dateien aus, klicken Sie auf „Stage“, wodurch sie zum Index hinzugefügt werden, und klicken Sie dann auf „Commit“. Daher werden nur die beiden ausgewählten Dateien in den Commit einbezogen.
Danach erscheint ein Fenster, in dem Sie einen Kommentar zum Commit eingeben müssen. Normalerweise schreiben sie dort, was geändert, hinzugefügt, entfernt usw. wurde:
Anschließend sollten Sie auf die Schaltfläche „Commit“ klicken. Die Schaltfläche „Commit & Push“ bewirkt das Gleiche, lädt aber auch die Änderungen in das Remote-Repository (in unserem Fall Bitbucket) hoch. Bis dahin tun Sie es nicht. Wir werden uns darum kümmern, weiter voranzutreiben. Unten in der Liste der Filialen wird angezeigt Lokale Niederlassung"Meister". Dies ist der Hauptzweig des Anwendungscodes. Was Filialen sind, erzähle ich etwas später. Und jetzt werden wir etwas mit unserem Projekt machen und dann die Änderungen rückgängig machen. Ich werde die Datei readme.txt löschen, die Datei index.php bearbeiten und eine neue Dateiconfic.cfg hinzufügen:
Lassen Sie uns nun die Änderung nach dem Commit rückgängig machen. Gehen wir zum Protokoll:
Wählen Sie den Commit aus, zu dem wir ein Rollback durchführen möchten, und klicken Sie auf „Zurücksetzen“:
Im nächsten Fenster werden wir aufgefordert, auszuwählen, welchen „Reset“ wir durchführen möchten:
Erklären wollen. Denken Sie daran, dass Sie beim Erstellen eines Commits zunächst die Dateien zur Bühne hinzufügen. Dadurch können Sie nur indizierte Dateien festschreiben. Beim Soft-Reset werden nur Commits zurückgesetzt. Der Index und die physischen Änderungen an den Dateien bleiben erhalten. Der gemischte Reset funktioniert auf die gleiche Weise wie die Software, entfernt jedoch auch den Dateiindex. Durch einen Hard-Reset werden Commits, Indizes und physische Änderungen an Dateien entfernt. Mit Vorsicht verwenden Hard-Reset, um den Überschuss nicht versehentlich zu entfernen.
Aus Gründen der Übersichtlichkeit habe ich einen Hard-Reset durchgeführt:
Wie Sie sehen, sind alle Änderungen in den Dateien verschwunden, bzw. alles wurde auf den Zustand des ersten Commits zurückgesetzt.
Nun ein wenig zum Erstellen von Zweigen. Warum werden sie überhaupt benötigt? Der Zweig ermöglicht Ihnen das Speichern Aktuellen Zustand Code und Experiment. Sie schreiben beispielsweise ein neues Modul. Es ist logisch, dies in einem separaten Zweig zu tun. Der Chef ruft an und sagt, dass es einen Fehler im Projekt gibt und dieser dringend behoben werden muss, aber Ihr Modul wurde nicht hinzugefügt. Wie lade ich nicht funktionierende Dateien hoch? Wechseln Sie einfach in den Arbeitszweig ohne Modul, beheben Sie den Fehler und laden Sie die Dateien auf den Server hoch. Und wenn die „Gefahr“ vorüber ist, arbeiten Sie weiter am Modul. Und dies ist eines von vielen Beispielen für die Vorteile von Filialen.
Versuchen wir, einen eigenen Zweig zu erstellen. Wir haben bereits eines, das ist Master. Es wird automatisch erstellt (falls es fehlt), wenn Sie Ihren ersten Commit durchführen. Erstellen wir einen weiteren Zweig und nennen ihn „new_future1“. Drücken Sie F7 oder klicken Sie unten im Reiter „Zweige“ mit der rechten Maustaste auf die Aufschrift „Lokale Zweige“ und wählen Sie in der Dropdown-Liste „Zweig hinzufügen“ aus:
Klicken Sie auf „Zweig hinzufügen und wechseln“, um sofort zum erstellten Zweig zu wechseln. Jetzt können Sie neue Commits erstellen, Dateien ändern, ohne sich Sorgen machen zu müssen. Da Sie immer einen Hauptzweig haben, zu dem Sie zurückkehren können. Wenn Sie einen Zweig wechseln, ändert Git die lokalen Dateien in diejenigen in diesem Zweig. Das heißt, wenn Sie einen neuen Zweig erstellen, etwas in der Datei index.php ändern und dann zum Hauptzweig wechseln, werden alle von Ihnen vorgenommenen Änderungen gelöscht. Wenn Sie zum erstellten Zweig zurückwechseln, werden die Änderungen wiederhergestellt.
Bisher haben wir vor Ort gearbeitet. Versuchen wir, die Werke unserer Arbeit auf den Server hochzuladen. Lassen Sie uns ein Commit im Zweig new_future1 erstellen. Wenn das Repository leer ist, und zwar leer, weil wir es vor einiger Zeit erstellt und nichts auf den Server hochgeladen haben, weist Bitbucket den Hauptzweig zu, der zuerst hochgeladen wurde. Wechseln Sie daher in den „Master“-Zweig und drücken Sie den „Push“-Button:
Als Nächstes werden Sie von SmartGit aufgefordert, die Filialverfolgung zu konfigurieren. Mit der Nachverfolgung können Sie die relevanten Zweige automatisch aktualisieren, wenn Sie Codeaktualisierungen herunterladen oder hochladen. Klicken Sie daher gerne auf „Konfigurieren“:
Wechseln Sie nun zu einem anderen Zweig und machen Sie dasselbe. Gehen wir zu Bitbucket und sehen uns an, was sich im Abschnitt „Commits“ geändert hat:
Wie Sie sehen, ist alles auf einen Remote-Server gelangt.
Lassen Sie uns nun die Zweige zusammenführen. Warum ist das nötig? Nehmen wir das gleiche Beispiel mit einem Modul. Früher oder später werden Sie es hinzufügen und müssen den Modulcode zum Hauptanwendungscode hinzufügen. Es reicht aus, die Zweige einfach zusammenzuführen. Wechseln Sie dazu in den Zweig, in dem Sie den Code zusammenführen möchten. In unserem Fall ist dies der Master. Klicken Sie dann mit der rechten Maustaste auf den Zweig, aus dem Sie den Code zusammenführen möchten, und wählen Sie „Zusammenführen“:
Und jetzt müssen noch die Änderungen des Master-Zweigs auf den Server übertragen werden. Wir laden die Änderung auf die gleiche Weise wie zuvor auf den Server hoch und erhalten:
Das ist alles für dieses Mal. Aufgrund der Bilder kam der Artikel groß raus. Senden Sie Ihre Antworten. Schreibe Fragen.
In diesem Kapitel geht es um den Einstieg in Git. Lassen Sie uns zunächst die Grundlagen von Versionskontrollsystemen erlernen, dann mit der Ausführung von Git auf Ihrem Betriebssystem fortfahren und es schließlich zum Laufen bringen. Am Ende dieses Kapitels wissen Sie, was Git ist und warum Sie es verwenden sollten, und Sie werden über ein System verfügen, das endlich betriebsbereit ist.
Über das Versionskontrollsystem
Was ist ein „Versionskontrollsystem“ und warum ist es wichtig? Ein Versionskontrollsystem ist ein System, das Änderungen an einer Datei oder einer Reihe von Dateien im Laufe der Zeit aufzeichnet und es Ihnen ermöglicht, später zu einer bestimmten Version zurückzukehren. Für die Versionierung von Dateien in diesem Buch verwenden wir als Beispiel Quelle Obwohl Sie die Versionskontrolle tatsächlich für fast jeden Dateityp verwenden können.
Wenn Sie Grafik- oder Webdesigner sind und jede Version eines Bildes oder Layouts speichern möchten (was höchstwahrscheinlich der Fall sein wird), ist ein Versionskontrollsystem (im Folgenden als VCS bezeichnet) genau das Richtige für Sie. Damit können Sie Dateien in den Zustand zurückversetzen, in dem sie sich vor den Änderungen befanden, und das Projekt in diesen Zustand zurückversetzen Ausgangszustand, sehen Sie die Veränderung, sehen Sie, wer zuletzt geändert etwas und hat das Problem verursacht, wer hat wann die Aufgabe gestellt und vieles mehr. Die Verwendung von VCS bedeutet im Allgemeinen auch, dass Sie das Problem problemlos beheben können, wenn etwas kaputt geht oder Dateien verloren gehen. Zusätzlich zu allem erhalten Sie das alles ohne zusätzlichen Aufwand.
Lokale Versionskontrollsysteme
Viele Leute nutzen das Kopieren von Dateien in ein separates Verzeichnis als Versionskontrollmethode (vielleicht sogar ein Verzeichnis mit Zeitstempel, wenn sie schlau genug sind). Dieser Ansatz ist aufgrund seiner Einfachheit sehr verbreitet, aber er ist unglaublich fehleranfällig. Es kann leicht passieren, dass man vergisst, in welchem Verzeichnis man sich befindet, und versehentlich die falsche Datei ändert oder die falschen Dateien kopiert.
Um dieses Problem zu lösen, haben Programmierer vor langer Zeit lokale VCSs mit einer einfachen Datenbank entwickelt, die alle Änderungen an Dateien aufzeichnet und so eine Revisionskontrolle ermöglicht.
Abbildung 1. Lokale Versionskontrolle.
Eines der beliebtesten VCS war das RCS-System, das auch heute noch auf vielen Computern verbreitet ist. Sogar beliebt operationssystem Mac OS X stellt den Befehl rcs nach der Installation der Entwicklertools bereit. RCS speichert Patches (Unterschiede zwischen Dateien) in einem speziellen Format auf der Festplatte und kann so den Status jeder Datei zu einem bestimmten Zeitpunkt wiederherstellen.
Zentralisierte Versionskontrollsysteme
Das nächste große Problem, mit dem Menschen konfrontiert sind, ist die Notwendigkeit, mit anderen Entwicklern zu interagieren. Um damit umzugehen, wurden zentralisierte Versionskontrollsysteme (TSKV) entwickelt. Systeme wie CVS, Subversion und Perforce verfügen über einen einzigen Server, der alle Dateiversionen speichert, und über eine Reihe von Clients, die Dateien aus diesem zentralen Repository abrufen. Der Einsatz von CSCR ist seit vielen Jahren der Standard.
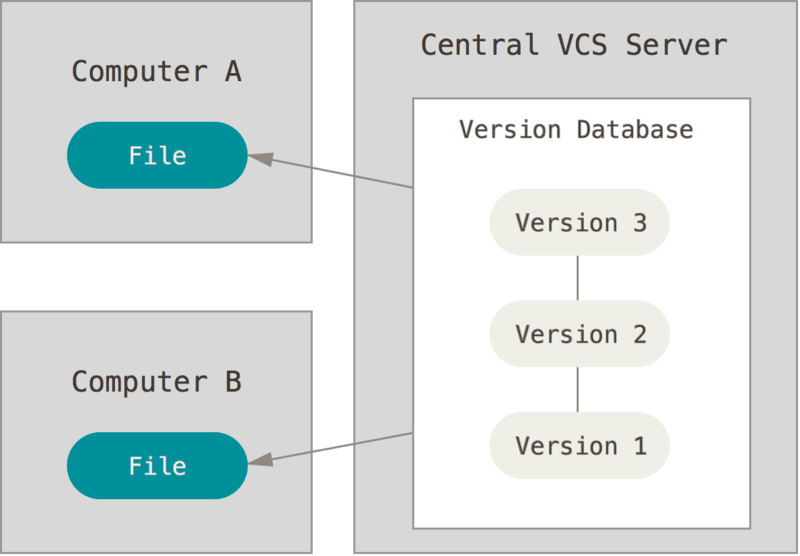
Abbildung 2. Zentralisierte Versionskontrolle.
Dieser Ansatz hat viele Vorteile, insbesondere gegenüber lokalem SLE. Beispielsweise wissen alle Projektentwickler einigermaßen, was jeder von ihnen tut. Administratoren haben die vollständige Kontrolle darüber, wer was tun kann, und es ist viel einfacher, den CSCM zu verwalten, als lokale Datenbanken auf jedem Client zu betreiben.
Dennoch hat dieser Ansatz auch gravierende Nachteile. Der offensichtlichste Nachteil ist der Single Point of Failure, den der zentralisierte Server darstellt. Wenn dieser Server eine Stunde lang ausfällt, kann während dieser Zeit niemand die Versionskontrolle verwenden, um die Änderungen, an denen er arbeitet, zu speichern, und niemand kann diese Änderungen mit anderen Entwicklern teilen. Wenn Festplatte, in der die zentrale Datenbank gespeichert ist, beschädigt ist und es keine zeitnahen Backups gibt, verlieren Sie alles – den gesamten Verlauf des Projekts, nicht mitgerechnet die einzelnen Repository-Snapshots, die auf den lokalen Rechnern der Entwickler gespeichert wurden. Lokale VCS leiden unter dem gleichen Problem: Wenn der gesamte Projektverlauf an einem Ort gespeichert wird, besteht die Gefahr, dass alles verloren geht.
Dezentrale Versionskontrollsysteme
Hier kommen dezentrale Versionskontrollsysteme (DSVs) ins Spiel. In DLCS (wie Git, Mercurial, Bazaar oder Darcs) laden Clients nicht nur einen Snapshot aller Dateien herunter (den Status der Dateien zu einem bestimmten Zeitpunkt), sondern kopieren das gesamte Repository. Wenn in diesem Fall einer der Server, über die die Entwickler kommuniziert haben, ausfällt, kann jedes Client-Repository auf einen anderen Server kopiert werden, um die Arbeit fortzusetzen. Jede Kopie des Repositorys ist eine vollständige Sicherung aller Daten.
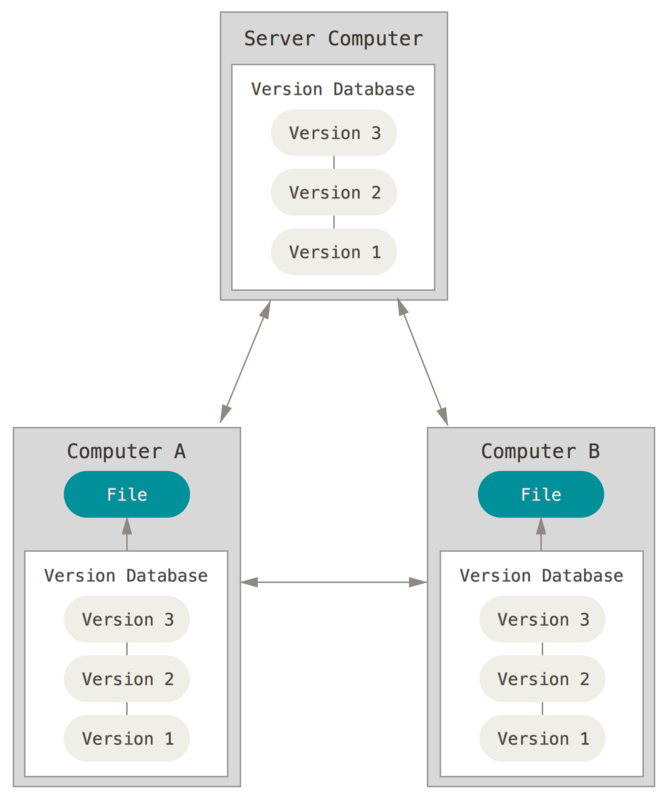
Abbildung 3. Dezentrale Versionskontrolle.
Darüber hinaus können viele CSVs gleichzeitig mit mehreren Remote-Repositorys interagieren, sodass Sie innerhalb desselben Projekts gleichzeitig mit verschiedenen Personengruppen und unterschiedlichen Ansätzen arbeiten können. Dadurch können Sie mehrere Entwicklungsansätze gleichzeitig anwenden, beispielsweise hierarchische Modelle, was in zentralisierten Systemen völlig unmöglich ist.
Möchten Sie in der Hälfte der Zeit an IT-Entwicklungsteamprojekten arbeiten? Nehmen Sie an unserem neuen Autorenkurs teil und lernen Sie, wie Sie Git optimal nutzen können!
Git ist ein verteiltes Versionskontrollsystem (VCS). Es ist universell, kostenlos und handliches Werkzeug Für Zusammenarbeit Programmierer für Projekte jeder Ebene. Mit Git können mehrere Entwickler gleichzeitig an ihren Teilaufgaben arbeiten und so gleichberechtigte Zweige erstellen. Gleichzeitig überschreibt jedes Speichern (Commit) in Git nicht das vorherige und Sie können jederzeit zur ursprünglichen Version des Codes zurückkehren.
Aus diesem Grund verwenden Millionen von Programmierern täglich Git bei ihrer Arbeit. Git macht Entwicklern das Leben einfacher mobile Anwendungen, Computerspiele, Open-Source-Software, Webprogrammierer. Git eroberte die IT-Welt mit Zuverlässigkeit, Hochleistung, bequemes Arbeiten mit Filialen und Unabhängigkeit vom Server.
Der Kurs wird nicht nur für Anfänger nützlich sein, sondern auch für erfahrene Entwickler, die Lücken in ihren Fähigkeiten im Umgang mit Git schließen möchten. Es wird in der Natur angewendet und zielt auf die Lösung spezifischer Probleme und Probleme ab, mit denen Entwickler konfrontiert sind.
Sie erfahren, was Versionskontrollsysteme sind und wie Git Codeänderungen verfolgt. Erfahren Sie, wie Sie das System installieren und konfigurieren. Sie können Zweige erstellen, diese zusammenführen und Konflikte im Code lösen. Üben Sie verteiltes Arbeiten und beherrschen Sie das Git-Toolkit.
Nehmen Sie an diesem einzigartigen Kurs teil und jedes Ihrer IT-Entwicklungsteamprojekte wird effektiv sein!