Все вы знаете систему Git. Хотя бы слышали - это наверняка. Разработчики, которые пользуются системой, ее или любят, или ругают за сложный интерфейс и баги. Система управления версиями Git де-факто является стандартом в индустрии. У разработчика могут быть мнения о преимуществах Mercurial, но чаще всего приходится мириться с требованием уметь пользоваться Git. Как у любой сложной системы, у нее множество полезных и необходимых функций. Однако, до гениальной простоты добираются не все, поэтому существующая реализация оставляла пространство для совершенствования.
Простыми словами - мудреным приложением было трудно пользоваться. Поэтому в лаборатории Массачусетского Технологического Института взялись за улучшения и отсекли все «проблемные элементы» (ведь то, что для одного проблема, для другого легко может быть преимуществом). Улучшенную и упрощенную версию назвали Gitless. Её разрабатывали с учетом 2400 вопросов, связанных с Git и взятых с сайта разработчиков StackOverflow.
Что не так с Git
Многие пользователи жаловались , что Git нуждается в новом интерфейсе. Специалисты даже составили документ Что не так с Git? Концептуальный анализ дизайна. Авторы: S. Perez De Rosso и D. Jackson.Пример
git checkout < file > // отбросить все изменения в одном файле с последней выгрузки в систему git reset --hard // отбросить все изменения во всех файлах с последней выгрузки в системуЭти две строчки - одна из иллюстраций того, как сильно Git нуждался в усовершенствованном интерфейсе. Две разные команды для одной функции с одной разницей в том, что одна для одиночного файла, а вторая - для множества файлов. Часть проблемы также в том, что эти две команды на самом деле не делают в точности одно и то же.
Большинство пользователей Git применяют его для небольшого числа команд, а оставшиеся единицы знают платформу на более глубоком уровне. Получается, что в основном платформа нужна для базовых функций, а большой пласт возможностей остается для слишком узкого круга. Это говорит о неправильной работе Git.
Краткое сравнение базовых функций с предыдущей версией
Одной из ярких характеристик Gitless является то, что версия игнорирует функцию под названием staging. Она позволяет сохранять отдельные части файла. Удобно, но может создавать проблемные ситуации. Ключевое отличие между этой и функцией stashing заключается в том, что вторая скрывает изменения из рабочей области.Функция stashing прячет черновую работу в рабочем каталоге - отслеживаемые файлы, которые были изменены и сохраняет все в стек с незавершенными изменениями. Все изменения можно применить позже, когда будет удобно. Это нужно, когда вы работаете в одной ветке и в ней все в беспорядочном состоянии, а нужно срочно переключиться на другую ветку. Вы не хотите выгружать код с частично сделанной работой в первой ветке на время паузы.
Функция staging индексирует изменения, внесенные в файл. Если вы пометили файлы staged, Git понимает, что вы подготовили их к выгрузке.
В Gitless нет концепции stashing. Представьте следующую ситуацию. Вы находитесь в разгаре разработки проекта и должны переключиться в другую его ветку, но вы еще не выгрузили в систему свою наполовину выполненную работу. Функция stashing берет сделанные вами изменения и сохраняет их в стек с неоконченными изменениями, которые вы можете восстановить позднее.
Автор руководства по Gitless сообщает, что проблема появляется при переключении между ветками. Может быть сложно запоминать какой из stashes где находится. Ну и вершиной всего этого стало то, что функция не помогает в случае когда вы в процессе мерджа, включающего в себя конфликтные файлы. Таково мнение Переза де Россо.
Благодаря Gitless эта проблема решается. Ветки стали полностью автономными по отношению друг к другу. Это делает работу намного проще и позволяет разработчикам избегать путаницы, когда нужно постоянно переключаться между задачами.
Сохранение изменений
Gitless прячет область стадий в целом, что делает процесс более прозрачным и менее сложным для пользователя. Для решения задач есть намного более гибкие команды «commit». Причем они позволят делать такие действия, как выделение сегментов кода для коммита.
Кроме этого вы можете изменить классификацию любого файла на значения: отслеживаемый, не отслеживаемый или игнорируемый. Не имеет никакого значения, существует ли этот файл в заголовке или нет.
Разветвление процессов разработки
Основная, необходимая для понимания новой версии, идея: ветки в Gitless стали абсолютно независимыми линиями разработки. Каждая из них остается при своей рабочей версией файлов отдельно от других. Пересечений и проблем нет. В какой момент вы бы ни переключались в другую ветвь, содержимое вашего рабочей области сохраняется и файлы, которые имеют отношение к ветке назначения, восстанавливаются. Классификация файлов также сохраняется. Если файл классифицирован по-разному в двух отдельных ветках, то Gitless будет учитывать это.
Проще говоря, в версии Gitless вам не нужно помнить о незагруженных в систему изменениях, которые находятся в конфликте с изменениями в ветке назначения.
Также вы сможете отложить решение конфликтной ситуации, если у вас середина мержда или fuse. Конфликт останется пока вы не переключитесь обратно.
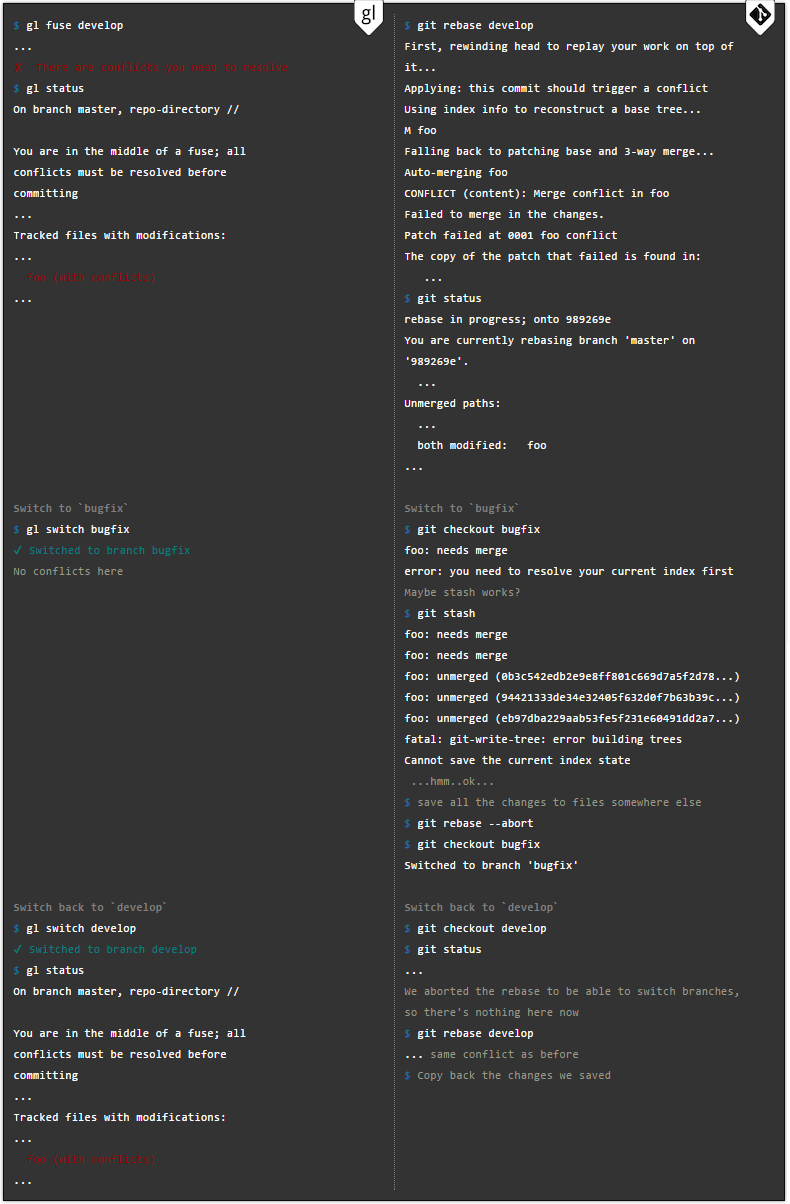
Работа с удаленными репозиториями
Вот синхронизация с прочими репозиториями происходит в обоих программах одинаково.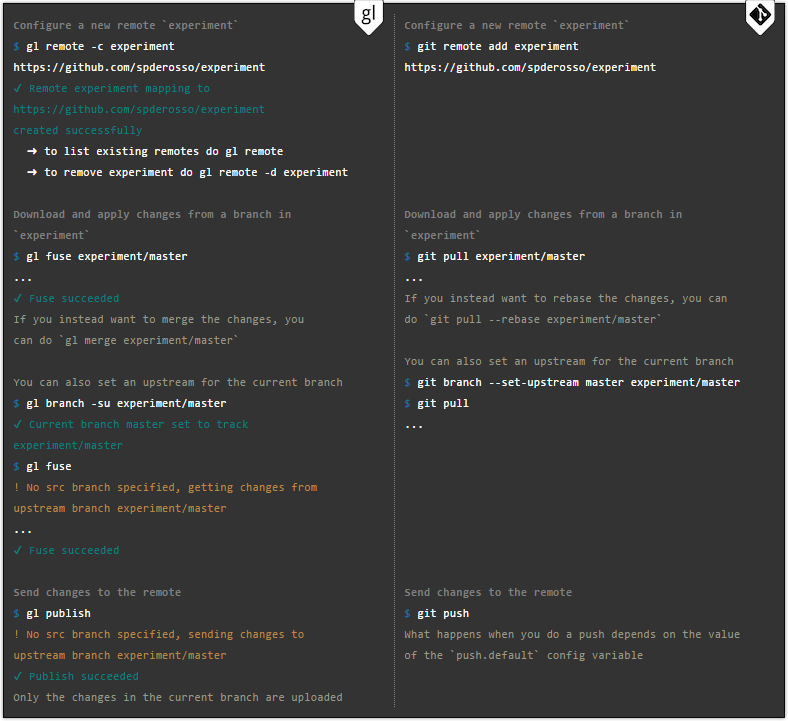
Ещё одно преимущество новой версии - возможность переключаться к старой без потери кода. При этом ваши коллеги могут быть даже не в курсе, что вы пользуетесь другим ПО.
Руководство по работе с Gitless вы можете изучить на официальном сайте приложения. В документации описано следующее: как создавать репозиторий, сохранять изменения; как работать с ветками; как пользоваться тэгами, работать с удаленными репозиториями.
Что в итоге
Получилось приложение, которое сохраняет функционал Git, но в то же время стало более простым в изучении и использовании командами разработки. На самом деле и до Gitless уже были попытки улучшить Git. Но по словам Филипа Гуо (он ассистент профессора когнитивной науки в Калифорнийском университете Сан-Диего) эта версия впервые достигла целей по преображению интерфейса и действительному решению главных проблем.Проект использовал строгие методы по созданию программного обеспечения. Это необходимо для вычленения недостатков в одном из наиболее широко применяемых во всем мире программных проектов. В прошлом множество пользователей приводили смешные аргументы как за, так и против Git, но все они не были основаны на научном подходе.
На примере Gitless становится очевидно, что подход упрощения возможно применять и к другим сложным системам. Например, Google Inbox и Dropbox.
Во время работы над проектом его участники часто сталкиваются с проблемами синхронизации и ведения истории файлов, решить которые помогают системы управления версиями (СУВ). Цель этой серии статей – познакомить читателя с принципами работы СУВ и подробно рассмотреть одну из них, а именно Git. Почему Git? В последнее время эта система набирает популярность, и ее важность для свободного ПО (и для проекта GNU/Linux, в частности) сложно переоценить.
Мы последовательно, в общих чертах, разберем характеристики систем контроля, расскажем об их архитектуре и основных особенностях рассматриваемого приложения. Кроме того, сделаем обзор ныне существующих интерфейсов для работы с Git.
Автор сознательно опускает терминологию функций, ключей и прочих тонкостей, чтобы четко, ясно и в общем виде представить вам картину. Данная статья предполагает, что читатель знаком с Unix-подобными операционными системами (ОС), а также имеет базовые знания в области алгоритмики и информатики в целом.
В следующих материалах мы углубимся в структуру и философию Git, специфику этой системы и тонкости практической работы с ней. Завершит цикл статья о взаимодействии Git с другими СУВ (такими как Subversion, CVS, Mercurial и др.).
2. Git – это...
Git – это распределённая система управления версиями файлов. Код программы написан в основном на языке С. Проект был создан Линусом Торвальдсом в 2005 году для управления разработкой ядра Linux и, как и GNU/Linux, является свободным программным обеспечением (ПО), при этом стороннее использование подчиняется лицензии GNU GPL версии 2. Вкратце данное соглашение можно охарактеризовать как ПО со свободным кодом, которое должно развиваться открыто, т.е. любой программист вправе продолжить совершенствование проекта на любом его этапе. За свое недолгое время существования данная система была введена многими ведущими разработчиками. Git используется в таких известных Linux-сообществу проектах, как Gnome, GNU Core Utilities, VLC, Cairo, Perl, Chromium, Wine.
3. Системы управления версиями
Системы управления версиями (Version Control Systems) – это программное обеспечение, призванное автоматизировать работу с историей файла (или группы файлов), обеспечить мониторинг изменений, синхронизацию данных и организовать защищенное хранилище проекта. Короче говоря, основная задача систем управления версиями – упростить работу с изменяющейся информацией. Разберем общий вид разработки на примере.
Предположим, есть некий проект, который вы разрабатываете, несколько отделов программистов и вы – координатор (или руководитель). По отношению к системе контроля, будь то сервер (если речь идет о централизованной системе) или локальная машина, любой разработчик проекта ограничен только правами доступа на изменение и/или чтение версий файлов данного хранилища. В любой момент вы можете сделать откат данных до необходимой вам версии. Вы, как координатор, можете ограничить доступ определенным пользователям на обновление версии файла. Также СУВ предоставляет интерфейс наблюдения и поиска версий файлов. Например, можно создать запрос: “Где и когда менялся данный кусок кода?”.
Система предполагает защищенное хранение данных, т.е. любой хранимый в ней блок имеет множество клонов. Так, например, при повреждении какого-либо файла вы своевременно можете заменить его копией. Для уменьшения объема данных проекта часто используется дельта-компрессия – такой вид хранения, при котором хранятся не сами версии файла, а только изменения между последовательными ревизиями.
4. Отличия распределённых систем управления версиями
Распределённые системы управления версиями – это СУВ, главной парадигмой которых является локализация данных каждого разработчика проекта. Иными словами, если в централизованных СУВ все действия, так или иначе, зависят от центрального объекта (сервер), то в распределенных СУВ каждый разработчик хранит собственную ветвь версий всего проекта. Удобство такой системы в том, что каждый разработчик имеет возможность вести работу независимо, время от времени обмениваясь промежуточными вариантами файлов с другими участниками проекта. Рассмотрим эту особенность, продолжая предыдущий пример.
У каждого разработчика на машине есть свой локальный репозиторий – место хранения версий файлов. Работа с данными проекта реализуется над вашим локальным репозиторием, и для этого необязательно поддерживать связь с остальными (пусть даже и главными) ветвями разработки. Связь с другими репозиториями понадобится лишь при изменении/чтении версий файлов других ветвей. При этом каждый участник проекта задает права собственного хранилища на чтение и запись. Таким образом, все ветви в распределенных СУВ равны между собой, и главную из них выделяет координатор. Отличие главной ветви лишь в том, что на неё мысленно будут равняться разработчики.
5. Основные возможности и особенности Git
Стоит сказать, что система если и не произвела фурор, то немного всколыхнула сообщество в области СУВ своей новизной и предложила новый путь развития. Git предоставляет гибкие и простые в использовании инструменты для ведения истории проекта.
Особенностью Git является то, что работа над версиями проекта может происходить не в хронологическом порядке. Разработка может вестись в нескольких параллельных ветвях, которые могут сливаться и разделяться в любой момент проектирования.
Git – довольно гибкая система, и область её применения ограничивается не только сферой разработки. Например, журналисты, авторы технической литературы, администраторы, преподаватели вузов вполне могут использовать её в своем роде деятельности. К таковым задачам можно отнести контроль версий какой-либо документации, доклада, домашних заданий.
Выделим основные отличия Git от других распределенных и централизованных СУВ.
Архитектура Git
SHA1 (Secure Hash Algorithm 1) – это алгоритм криптографического хеширования. Каждый файл вашего проекта в Git состоит из имени и содержания. Имя – это первые 20 байтов данных, оно наглядно записывается сорока символами в шестнадцатеричной системе счисления. Данный ключ получается хешированием содержимого файла. Так, например, сравнив два имени, мы можем почти со стопроцентной вероятностью сказать, что они имеют одинаковое содержание. Также, имена идентичных объектов в разных ветвях (репозиториях) – одинаковы, что позволяет напрямую оперировать данными. Хорошим дополнением сказанному выше служит ещё то, что хеш позволяет точно определить поврежденность файлов. Например, сравнив хеш содержимого с именем, мы можем вполне точно сказать, повреждены данные или нет. Далее под именем мы будем понимать имя файла, а строку символов будем называть SHA1-хешем.
Стоит упомянуть о так называемых коллизиях. “Вполне точно определить поврежденность” означает, что существуют такие файлы, различные по содержанию, SHA1-хеш которых совпадает. Вероятность таких коллизий очень мала, и по предварительной оценке равна 2 в -80-й степени (~ 10 в -25-й степени). Точной оценки нет, так как на данный момент мировому сообществу не удалось эффективно расшифровать данную криптографическую схему.
Объекты Git
Работу с версиями файлов в Git можно сравнить с обычными операциями над файловой системой. Структура состоит из четырех типов объектов: Blob, Tree, Commit и References; некоторые из них, в свою очередь, делятся на подобъекты.
Blob (Binary Large Object) – тип данных, который вмещает лишь содержимое файла и собственный SHA1-хеш. Blob является основным и единственным носителем данных в структуре Git. Можно провести параллель между данным объектом и инодами (inodes) в файловых системах, поскольку их структура и цели во многом схожи.
Дерево (Tree)
- собственный SHA1-хеш;
- SHA1-хеш blob’ов и/или деревьев;
- права доступа Unix-систем;
- символьное имя объекта (название для внутреннего использования в системе).
По своей сути объект является аналогом директории. Он задает иерархию файлов проекта.
Commit – тип данных, который содержит:
- собственный SHA1-хеш;
- ссылку ровно на одно дерево;
- ссылку на предыдущий commit (их может быть и несколько);
- имя автора и время создания commit’а;
- имя коммитера (commiter – человек, применивший commit к репозиторию, он может отличаться от автора) и время применения commit’а;
- произвольный кусок данных (блок можно использовать для электронной подписи или, например, для пояснения изменений commit’а).
Данный объект призван хранить снимок (версию) группы файлов в определенный момент времени, можно сравнить его с контрольной точкой. Commit’ы можно объединять (merge), разветвлять (branch) или, например, установить линейную структуру, тем самым отражая иерархию версий проекта.
Reference – тип данных, содержащий ссылку на любой из четырех объектов (Blob, Tree, Commit и References). Основная цель его – прямо или косвенно указывать на объект и являться синонимом файла, на который он ссылается. Тем самым повышается понимание структуры проекта. Очень неудобно оперировать бессмысленным набором символов в названии, ссылку же, в отличие от SHA1-хеша, можно именовать так, как удобнее разработчику.
Из ссылок, в свою очередь, можно выделить ряд подобъектов, имеющих некоторые различия: Ветвь, Тег. Рассмотрим их.
Ветвь (Head, Branch) – символьная ссылка (Symbolic link), которая указывает на последний в хронологии commit определенной ветви и хранит SHA1-хеш объекта. Является типом данных журналируемых файловых систем. Данный вид объекта определяется не в самом Git, а наследуется от операционной и файловой систем. Ветвь используется как синоним файла, на который она ссылается, т.е. Git позволяет оперировать ею напрямую. Можно позволить себе не задумываться о том, работаете ли вы с последней версией или нет.
Тег (tag) – тип данных, который в отличие от ветвей неизменно ссылается на один и тот же объект типа blob, tree, commit или tag. Его, в свою очередь, можно разделить на легковесный (light tag) и тяжеловесный или аннотированный (annotated tag). Легкий тег, кроме неизменности ссылки, ничем не отличается от обычных ветвей, т.е. содержит лишь SHA1-хеш объекта, на который ссылается, внутри себя. Аннотированный тег состоит из двух частей:
- первая часть содержит собственный SHA1-хеш;
- вторая часть состоит из:
- SHA1 объекта, на который указывает аннотированный тег;
- тип указываемого объекта (blob, tree, commit или tag);
- символьное имя тега;
- дата и время создания тега;
- имя и e-mail создателя тега;
- произвольный кусок данных (данный блок можно использовать для электронной подписи или для пояснения тега).
Иными словами, проект в Git представляет собой набор blob’ов, которые связаны сетью деревьев. Полученная иерархическая структура может, в зависимости от времени, быть отражена в виде commit’ов – версий, а для понимания их структуры в Git присутствуют такие объекты, как ссылки. Исключая действия со ссылками, почти вся работа с объектами системы максимально автоматизирована изнутри. Отталкиваясь от механизма ссылок, мы приходим к следующей идее – работать именно над группами файлов. По мнению автора, мысль является ключевой в философии Git. Задав, например, операцию для данного commit’а, она рекурсивно отработает свою часть по дереву, на которое ссылается. Являясь расширением общепринятого взгляда “действие над каждым файлом”, нововведение упрощает реализацию и подход со стороны программиста над повседневными задачами СУВ, такими как слияние/разделение ветвей, опять же рекурсивно автоматизируя процесс. Данный подход прост для понимания, быстро работает и гибок в реализации своих целей. Многие из этих черт достигаются благодаря Unix-ориентированности системы, т.е. оперируя стандартными устройствами, Git опирается на уже имеющиеся в операционной системе решения.
Проясним момент хранения данных. Содержание файлов разных версий в хронологии занимает довольно много памяти. Так, например, в проекте из двадцати файлов двадцати версий архив будет весить в 20 раз больше (возможно, порядка сотни мегабайтов), а что будет, если количество и тех и других в 10 раз больше (вроде бы не намного)? Размер занятого пространства возрастет в 100 раз (т.е. примерно 1 ГБ). В реальных задачах скорость роста занимаемой памяти далеко не линейно зависит от времени. Для решения данной проблемы существует несколько оптимизаций:
- каждый объект Git хранится в виде обыкновенного архива (tar.gz);
- для всей иерархии файлов применяется последовательная дельта-компрессия.
Разберем на примере.
У вас есть трехлетняя история вашего проекта, в ней порядка тысячи файлов и ста версий. Если в определенный момент нужно будет обратиться к самой ранней версии, Git придется разархивировать дельта-компрессию всей истории файла. Неутешительно, но на данный процесс может уйти до полудня. Git предлагает делать так называемые контрольные точки, т.е. хранить недельта-архивированный файл через некоторое количество версий, которое назовем глубиной компрессии. Тогда в нашем примере вся история сужается до некоторого наперед заданного количества дельта-компрессий, разархивировав которые, можно взглянуть на любую версию в хронологии. Заметим, что дельта-компрессию наиболее целесообразно использовать над одними видами ближайших в иерархии объектов, для этого репозиторий необходимо отсортировать соответственно по типу и размеру. Данный ряд операций, описанных в этом пункте, выполняет функция git-repack (и git-gc, которая её содержит).
Слияние и разделение ветвей
Данный вопрос очень трудоемок и насыщен, в связи с чем введем понятия слияния и разделения только в общих чертах. Снова обратимся к примеру.
Представим себе момент разработки проекта, когда главной поставленной целью является скорость работы программы. Один из возможных тактических вариантов решения – разбить разработчиков на две группы, каждая из которых будет решать одну и ту же задачу. При этом ветвь истории проекта должна раздвоиться. Данная процедура называется ветвление (branch). Действие разветвления ветви – это простое создание её копии, которая впоследствии будет иметь свою историю.
Пусть мы получили два уже законченных результата одной и той же задачи, над которой работали две группы программистов. Как нам быть? Посмотреть, чей код быстрее и надежнее? Это слишком просто, но не всегда лучший выход. Хорошее решение – это, немного разобравшись в коде и файлах, разбить их на подзадачи или блоки кода. И только тогда уже выявлять сильные и слабые стороны данных кусочков. Конечно, этот вариант подходит только в том случае, когда вы заранее предусмотрели, что впоследствии сможете собрать все эти частицы воедино. Случай, когда вы сами разрабатываете код, улучшая и исправляя некоторые ошибки, равнозначен приведенному примеру. Данный процесс объединения двух целых в одно называется слияние (merge). Процесс объединения двух версий и есть ключевой момент ведения проекта. Как бы то ни было, стоит избегать автоматизированного исполнения данной операции. Отличительная черта Git – это максимально достоверный и довольно быстрый способ решения задачи ветвления.
К достоинствам системы можно отнести:
- Unix-ориентированность.
- Идеологическая выдержанность (следуя правилам использования системы, очень сложно попасть в безвыходную ситуацию или получить то, чего вы не ожидали).
- Высокая производительность (это одно из самых явных достоинств системы, плата за которое есть «Идеологическая выдержанность» и «Unix-ориентированность»).
- Интеграция Git со сторонними СУВ, такими как Subversion, Mercurial, …
- Управление группой файлов (системе нет необходимости рассматривать изменения в каждом файле по отдельности, она запоминает любые изменения всего проекта, и если вдруг вам понадобится проследить единичные изменения, она выдаст ровно ту часть, которая связана с данным файлом).
- Операция слияния (максимально автоматизированная реализация сложной задачи).
К недостаткам отнесем:
- Unix-ориентированность (стоит отметить отсутствие зрелой реализации Git на не Unix-системах).
- Необходимость периодического выполнения команды git-gc (пакует группы файлов и удаляет те, которые не связанны ссылками).
- Коллизии хеширования (совпадение SHA1 хеша различных по содержанию файлов).
6. Интерфейсы Git
«Сколько людей, столько и мнений». Попробуем выделить ряд типов интерфейсов для работы с системой. Для определенных целей по-своему лучше каждое из приведеных ниже видов приложений.
Для людей, которые не занимаются разработкой вплотную, для «консерваторов» – тех, кто любит “кнопочки и галочки” и сознательно хочет оградить себя от непомерных усилий запоминания функций, ключей и многих тонкостей, больше подойдет вариант в стиле TortoiseGit или Git Extensions – простые интерфейсы. Они позволяют действовать преимущественно мышью и работают в привычной для многих ОС Windows.
Ровно противоположный тип интерфейса. Для программистов, которым постоянно необходимо взаимодействовать с сотрудниками, решать типичные задачи контроля именно кода, для людей, которые привыкли работать в Unix-like системах, используя терминал, лучше всего подойдет консольный вид приложений. Они так же просты в обращении, немного быстрее и функциональнее, но им придется уделить время, для того чтобы разобраться в использовании.
Можно выделить и третий тип интерфейсов – смешение первых двух. Т.е. у вас есть консольное приложение, например, “родная” оболочка git. Вы можете использовать ряд дополнительных утилит, таких как Gitk или QGit, для отображения деревьев, упрощения обзора иерархии версий, различий между версиями, поиска нужных объектов.
7. Заключение
Итак, читатели уже представляют себе, как работают современные системы контроля версий. Кроме того, нами была рассмотрена архитектура одной из самых популярных систем – Git. В следующей статье мы попробуем на практике познакомиться с некоторыми ее особенностями – рассмотрим функции и ключи к ним. В статье будет дан ряд наглядных примеров ведения истории файлов, а также изложена философия распределенных систем. Автор попытается показать читателям, как можно правильно использовать Git и рассмотрит некоторые типичные ошибки использования этой СУВ.
Понадобилось мне недавно обучить азам Git нескольких моих сотрудников, которые только изучают программирование и пробуют работать. Поискав в интернете статьи для новичков, я столкнулся с тем, что большинство из них про то как использовать консольный Git или же про его необходимость и преимущество перед другими подобными системами. Новичок обычно не очень силен во всех этих делах. Я считаю, что ему, для начала, и знать это все не обязательно. Ведь можно использовать Git для своих проектов и учиться всем его прелестям параллельно с изучением программирования. Но, настоятельно рекомендую воспринимать эту статью как ознакомительную и в будущем изучить Git подробнее .
В общем, под катом статья, как используя SmartGit и BitBucket можно улучшить свою жизнь начинающего разработчика.
М аленький план того, что мы будем делать:
- Создание репозитория на Bitbucket.
- Клонирование репозитория (добавление его в SmartGit).
- Создание комитов.
- Отмена изменений.
- Создание веток.
- Проталкивание веток на удаленный репозиторий (аплоад веток на удаленный сервер).
- Слияние веток.
Поехали. Создание репозитория очень простая задача. Мы будем для этого пользоваться BitBucket, поэтому вам нужно иметь там аккаунт. После регистрации жмем кнопку «Create» и заполняем необходимые поля. Склонируем репозиторий используя SmartGit. Возьмем ссылку на наш репозиторий.
Теперь запустим SmartGit, выберем «Project» - «Clone» (или Ctrl + Alt + O) и заполним необходимые поля:
Система запросит ваш логин и пароль от Bitbucket:
В следующем окне доступны две опции клонирования «Include Submodules» и «Fetch all Heads and Tags». Git позволяет отдельные модули приложения хранить в разных репозиториях. Если вы отметите опцию «Include Submodules» - SmartGit автоматически подгрузит все модули. Если отметить опцию «Fetch all Heads and Tags», то SmartGit после создания папки проекта скачает все ветки и теги для данного репозитория:
Следующее окно - имя проекта в SmartGit:
Если вы клонировали пустой репозиторий (как в этой статье), то увидите следующее окно:
Идем дальше. Создадим комит. Что такое комит? Это фиксация изменений. Каждый комит «запоминает» что именно вы изменили и в любой момент времени можно вернуть прежнее состояние файлов. Советую вам после каждого значимого изменения, например, исправление бага в функции, делать комит. Что бы создать комит, нужно что-то изменить в проекте. Добавьте парочку файлов в папку с проектом:
Теперь можно увидеть изменения нашего проекта в SmartGit:
Выберем оба файла и нажмем сначала «Stage», а потом «Commit». Зачем нужно нажимать «Stage»? Кнопка «Stage» добавляет в текущий индекс выбранные файлы. Если вы хотите создать комит для двух файлов, а изменили, предположим целых 5, достаточно выбрать эти два файла, нажать «Stage», что добавит их в индекс, а после «Commit». Таким образом только выбранные два файла попадут в комит.
После чего появится окошко, где нужно будет ввести комментарий комита. Обычно туда пишут то, что было изменено, добавлено, удалено и так далее:
После чего следует нажать кнопку «Commit». Кнопка «Commit & Push» делает тоже самое, но еще и проталкивает (заливает) изменения в удаленный репозиторий (в нашей случае это Bitbucket). Пока не стоит этого делать. Проталкиванием мы займемся далее. Внизу, в списке веток, появится локальная ветка «master». Это основная ветка кода приложения. Что такое ветки, расскажу чуть позже. А сейчас сделаем что-нибудь с нашим проектом, а потом откатим изменения. Я удалю файл readme.txt, отредактирую файл index.php и добавлю новый файл confic.cfg:
А теперь откатим изменение после комита. Зайдем в Log:
Выберем комит, к которому хотим откатиться и нажмем «Reset»:
В следующем окне нам предлагают выбрать какой именно «Reset» мы хотим сделать:
Объясню. Вспомните, что при создании комита, вы сначала добавляете файлы в индекс (stage). Это позволяет закомитить только проиндексированные файлы. Soft reset сбрасывает только комиты. Индекс и физические изменения в файлах остаются. Mixed reset работает так же, как и софт, но еще удаляет индекс файлов. Hard reset удаляет комиты, индекс и физические изменения в файлах. Аккуратно используйте hard reset, что бы нечаянно не удалить лишнего.
Я сделал hard reset для наглядности:
Как видите все изменения в файлах пропали, а точнее все вернулось к состоянию первого комита.
Теперь немного о создании веток. Зачем они вообще нужны? Ветка позволяет сохранить текущее состояние кода, и экспериментировать. Например, вы пишите новый модуль. Логично делать это в отдельной ветке. Звонит начальство и говорит, что в проекте баг и срочно нужно пофиксить, а у вас модуль не дописан. Как же заливать нерабочие файлы? Просто переключитесь на рабочую ветку без модуля, пофиксите баг и заливайте файлы на сервер. А когда «опасность» миновала - продолжите работу над модулем. И это один из многих примеров пользы веток.
Попробуем создать свою ветку. У нас уже одна есть, это master. Она создается автоматически (если отсутствует) когда вы делаете первый комит. Создадим еще одну ветку и назовем ее «new_future1». Нажмите F7 или правым кликом внизу во вкладке «Branches» на надпись «Local Branches» и в выпадающем списке выберите «Add branch»:
Нажмите «Add branch & Switch» что бы сразу переключиться на созданную ветку. Теперь вы можете создавать новые комиты, изменять файлы и не беспокоиться. Так как у вас всегда есть ветка мастер, в которую можно вернуться. Когда вы переключаете ветку, Git меняет локальные файлы на те, которые есть в этой ветке. То есть, если вы создадите новую ветку поменяете что-то в файле index.php, а потом переключитесь на ветку master то все изменения, произведенные вами будут удалены. Если же переключиться обратно в созданную ветку - изменения вернутся.
До сих пор мы работали локально. Попробуем залить труды нашей работы на сервер. Создадим какой-нибудь комит в ветке new_future1. В случае если репозитарий пуст, а он пуст, так как мы создали его некоторое время назад и на сервер ничего не залили, Bitbucket основной назначает ту ветку, которую залили первой. Поэтому переключимся на ветку «master» и нажмем кнопку «Push»:
Дальше SmartGit спросит настроить ли отслеживание ветки (cofigure tracking). Отслеживание позволяет автоматически обновлять соответствующие ветки, когда вы скачиваете или загружаете обновления кода. Поэтому смело жмите «Configure»:
Теперь переключитесь на другую ветку и проделайте тоже самое. Зайдем на Bitbucket и посмотрим, что изменилось в разделе «Commits»:
Как видите все попало на удаленный сервер.
Теперь сольем ветки. Зачем это нужно? Возьмем тот же пример с модулем. Рано или поздно вы допишите его и вам нужно будет добавить код модуля в основной код приложения. Достаточно просто слить ветки. Для этого переключитесь на ветку, в которую хотите слить код. В нашем случае это мастер. После чего нажмите правым кликом на ветку, с которой хотите слить код и выберите «Merge»:
А теперь осталось протолкнуть изменения ветки master на сервер. Заливаем изменение на сервер так же, как мы делали это раньше и получаем:
Вот и все на этот раз. Из-за картинок статья вышла большой. Задавайте свои ответы. Пишите вопросы.
Эта глава о том, как начать работу с Git. Вначале изучим основы систем контроля версий, затем перейдём к тому, как запустить Git на вашей ОС и окончательно настроить для работы. В конце главы вы уже будете знать, что такое Git и почему им следует пользоваться, а также получите окончательно настроенную для работы систему.
О системе контроля версий
Что такое "система контроля версий", и почему это важно? Система контроля версий - это система, записывающая изменения в файл или набор файлов в течение времени и позволяющая вернуться позже к определённой версии. Для контроля версий файлов в этой книге в качестве примера будет использоваться исходный код программного обеспечения, хотя на самом деле вы можете использовать контроль версий практически для любых типов файлов.
Если вы графический или web-дизайнер и хотите сохранить каждую версию изображения или макета (скорее всего, захотите), система контроля версий (далее СКВ) - как раз то, что нужно. Она позволяет вернуть файлы к состоянию, в котором они были до изменений, вернуть проект к исходному состоянию, увидеть изменения, увидеть, кто последний менял что-то и вызвал проблему, кто поставил задачу и когда, и многое другое. Использование СКВ также значит в целом, что, если вы сломали что-то или потеряли файлы, вы спокойно можете всё исправить. В дополнение ко всему вы получите всё это без каких-либо дополнительных усилий.
Локальные системы контроля версий
Многие люди в качестве метода контроля версий применяют копирование файлов в отдельную директорию (возможно даже, директорию с отметкой по времени, если они достаточно сообразительны). Данный подход очень распространён из-за его простоты, однако он невероятно сильно подвержен появлению ошибок. Можно легко забыть, в какой директории вы находитесь, и случайно изменить не тот файл или скопировать не те файлы, которые вы хотели.
Для того, чтобы решить эту проблему, программисты давным-давно разработали локальные СКВ с простой базой данных, которая хранит записи о всех изменениях в файлах, осуществляя тем самым контроль ревизий.
Figure 1. Локальный контроль версий.
Одной из популярных СКВ была система RCS, которая и сегодня распространяется со многими компьютерами. Даже популярная операционная система Mac OS X предоставляет команду rcs , после установки Developer Tools. RCS хранит на диске наборы патчей (различий между файлами) в специальном формате, применяя которые она может воссоздавать состояние каждого файла в заданный момент времени.
Централизованные системы контроля версий
Следующая серьёзная проблема, с которой сталкиваются люди, - это необходимость взаимодействовать с другими разработчиками. Для того, чтобы разобраться с ней, были разработаны централизованные системы контроля версий (ЦСКВ). Такие системы, как: CVS, Subversion и Perforce, имеют единственный сервер, содержащий все версии файлов, и некоторое количество клиентов, которые получают файлы из этого централизованного хранилища. Применение ЦСКВ являлось стандартом на протяжении многих лет.
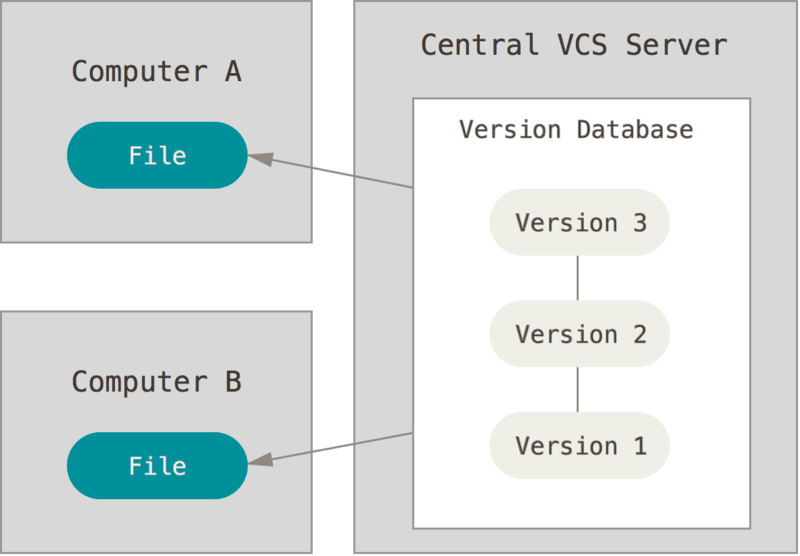
Figure 2. Централизованный контроль версий.
Такой подход имеет множество преимуществ, особенно перед локальными СКВ. Например, все разработчики проекта в определённой степени знают, чем занимается каждый из них. Администраторы имеют полный контроль над тем, кто и что может делать, и гораздо проще администрировать ЦСКВ, чем оперировать локальными базами данных на каждом клиенте.
Несмотря на это, данный подход тоже имеет серьёзные минусы. Самый очевидный минус - это единая точка отказа, представленная централизованным сервером. Если этот сервер выйдет из строя на час, то в течение этого времени никто не сможет использовать контроль версий для сохранения изменений, над которыми он работает, а также никто не сможет обмениваться этими изменениями с другими разработчиками. Если жёсткий диск, на котором хранится центральная БД, повреждён, а своевременные бэкапы отсутствуют, вы потеряете всё - всю историю проекта, не считая единичных снимков репозитория, которые сохранились на локальных машинах разработчиков. Локальные СКВ страдают от той же самой проблемы - когда вся история проекта хранится в одном месте, вы рискуете потерять всё.
Децентрализованные системы контроля версий
Здесь в игру вступают децентрализованные системы контроля версий (ДСКВ). В ДСКВ (таких как Git, Mercurial, Bazaar или Darcs), клиенты не просто скачивают снимок всех файлов (состояние файлов на определённый момент времени): они полностью копируют репозиторий. В этом случае, если один из серверов, через который разработчики обменивались данными, умрёт, любой клиентский репозиторий может быть скопирован на другой сервер для продолжения работы. Каждая копия репозитория является полным бэкапом всех данных.
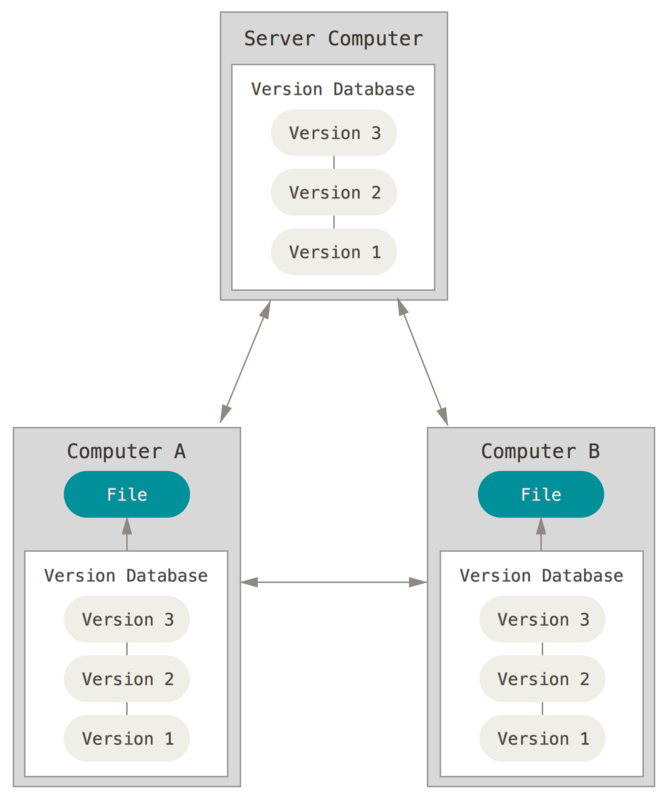
Figure 3. Децентрализованный контроль версий.
Более того, многие ДСКВ могут одновременно взаимодействовать с несколькими удалёнными репозиториями, благодаря этому вы можете работать с различными группами людей, применяя различные подходы единовременно, в рамках одного проекта. Это позволяет применять сразу несколько подходов в разработке, например, иерархические модели, что совершенно невозможно в централизованных системах.
Хотите работать над командными проектами по ИТ-разработке в два раза быстрее? Пройдите наш новый авторский курс и научитесь использовать все преимущества Git!
Git – распределенная система управления версиями (VCS). Это универсальный, свободный и удобный инструмент для командной работы программистов над проектами любого уровня. Git позволяет нескольким разработчикам работать одновременно над своими подзадачами, создавая равноправные ветви. При этом каждое сохранение (коммит) в Git не перезаписывает предыдущее, и в любой момент Вы сможете вернуться к исходной версии кода.
Именно поэтому миллионы программистов используют Git в своей работе каждый день. Git облегчает жизнь разработчикам мобильных приложений, компьютерных игр, СПО, веб-программистам. Git покорил ИТ-мир надёжностью, высокой производительностью, удобством работы с ветками и независимостью от сервера.
Курс будет полезен не только начинающим, но и опытным разработчикам, желающим ликвидировать пробелы в навыках использования Git. Он носит прикладной характер и направлен на решение конкретных задач и вопросов, с которыми сталкиваются разработчики
Вы узнаете, какие бывают системы управления версиями и как Git отслеживает изменения кода. Научитесь устанавливать и настраивать систему. Сможете создавать ветви, производить их слияние и устранять конфликты в коде. Попрактикуетесь в распределённой работе и освоите инструментарий Git.
Пройдите этот уникальный курс – и любой Ваш командный проект по ИТ-разработке будет эффективным!



